MessagePackフォーマット仕様にTimestamp型を追加
MessagePackフォーマット仕様のPull Request #209をマージし、MessagePackにTimestamp型を追加しました。
※この記事の英語版は XXX にあります(翻訳中)
Extension型の型コード -1 として定義されているため、後方互換性が維持されています。つまり、既にExtension型に対応しているデシリアライザであれば、Timestamp型を使用して作成されたデータを、Timestamp型に対応していない古いデシリアライズで読み出すことができます。
新しいTimestamp型には timestamp 32、timestamp 64、timestamp 96 の3つのフォーマットがあり、よく使う値をより少ないバイト数で保存できるようになっています。例えば、1970年〜2106年までの時刻で、秒までの精度しか持たない時刻であれば、合計6バイトで保存できます。1970年〜2514年までの時刻であれば、ナノ秒精度まで含めて10バイト。それを超える場合のみ、-584554047284年〜584554051223年までのナノ秒精度の時刻を15バイトで保存できます。
仕様にはシリアライズ・デシリアライズを行う簡単なコードなコードをも付属しています。Javaによる実装は msgpack/msgpack-java#431 のようになるでしょう。
ライブラリの実装では、2013年にRaw型からBinary型とString型を分離したケースと同様に、Timestamp型のデシリアライズにマイナーバージョンアップで対応し、Timestamp型のシリアライズをデフォルトの挙動として行う対応をメジャーバージョンアップで対応する方法が推奨されます。
さて、Timestamp型の追加については、次の3つの懸念点がありました。ここでは仕様を決めた背景について書きたいと思います。
タイムゾーン
MessagePackのTimestamp型は、タイムゾーンに関する情報を保存しません。常に1970年1月1日 00:00:00 UTCからの経過秒を保存することになります。
まず「時刻」という概念を整理すると、次のように分類することができます*1:
- 概念時刻(Local Time)
- グレゴリオ暦 例:2017-08-09 18:25:00
- その他の暦(和暦など)
- 絶対時刻(Instant)
概念時刻は、世界のどこのタイムゾーンで扱うかによって別の瞬間を示します。例えば 2017-08-09 18:25:00 は、どのタイムゾーンで解釈するかによって実際の時刻が変わるため、概念時刻です。概念時刻は、理論上は暦(calendar system)に依存していくつかの表現方法がありますが、普通はグレゴリオ暦(西暦)を使います。
絶対時刻は、世界中のどこで扱っても、同じ一瞬の時間を示します。例えば 2017-08-09 18:25:00 -0700 は、絶対時刻です。絶対時刻にもいくつかの表現方法があり、それぞれに利害得失があります。
UNIX時刻はもっともシンプルな方法で、タイムゾーンや暦に依存せず、常に1970年1月1日 00:00:00.000 UTCからの経過時間で時刻を表現します。タイムゾーンに関する情報は保存しません。
概念時刻にオフセットを加える方法は、年月日・時分秒を表示してくれるので、人間が見て分かりやすいという利点があります。
概念時刻にタイムゾーン名を加える方法は、「1日後」や「1週間前」といった暦に基づいた時刻の計算が簡単にできるという利点があります。例えば、米国の太平洋時間では、2017-03-12 00:00:00 -0800 の1日後は 2017-03-13 00:00:00 -0700 です。この間には夏時間の切り替えがあるため、オフセットが変化します。暦の上では1日後ですが、24時間後ではなく23時間後です。一方で、タイムゾーン名は夏時間の切り替えにかかわらず、太平洋時間を採用する地域では America/Los_Angeles です。つまり2017-03-12 00:00:00 America/Los_Angeles の1日後は、単に 2017-03-13 00:00:00 America/Los_Angelesです。一方で、絶対時間を得るためには、タイムゾーンの名前から意味(いつから夏時間が始まるか等)を引く必要があります。このためのデータベースはTime Zone Databaseと呼ばれ、IANAで管理されており、たまに変わります。最近では、ハイチ共和国が2017年に夏時間の慣習を変更したため、データベースが更新されました。
言語やデータベースシステムの型システムでは、次のように表現されています:
- MySQL
- DATETIME: 概念時刻
- TIMESTAMP: 絶対時刻
- PostgreSQL
- Java
- Go
- Time: 絶対時刻(概念時刻 + オフセット or タイムゾーン名)
- Ruby
- Time: 絶対時刻(UNIX時刻)
- DateTime: 概念時刻
- ActiveSupport::TimeWithZone: 絶対時刻(概念時刻 + オフセット or タイムゾーン名)
- Python
- datetime: 絶対時刻(概念時刻 + オフセット or タイムゾーン名)
- C (time.h: C99 + TC2)
- struct timespec: 絶対時刻(UNIX時刻)
- struct tm: 概念時刻
MessagePackでは、絶対時刻(UNIX時刻)を扱います。
タイムゾーン情報を含めなかった理由は、MessagePackは機械が高速に効率良く扱えるフォーマットを目指しており、また人間に表示する場合でも、その人間がいる場所のタイムゾーン情報を表示する時に付与するという方法で、表示上の課題はおおよそ解決できると考えたからです。タイムゾーン情報が本当に必要であれば、タイムゾーン名を別のフィールドで保存することもできます。例えば次のAやBの代わりに、Cを使用すれば良いでしょう:
A (概念時刻 + オフセットをタイムスタンプの値ごとに保存):
"user": {
"last_login": "2017-08-09T18:25:00-0700",
"signup": "2017-03-12T00:00:00-0800"
}
B (概念時刻 + タイムゾーン名をタイムスタンプの値ごとに保存):
"user": {
"last_login": "2017-08-09T18:25:00[America/Los_Angeles]",
"signup": "2017-03-12T00:00:00[America/Los_Angeles]"
}
C (絶対時刻をUNIX時刻/UTCで保存、タイムゾーン名を別フィールドに保存):
"user": {
"last_login": "2017-08-10T01:25:00Z",
"signup": "2017-03-12T08:00:00Z",
"timezone": "America/Los_Angeles"
}
精度
MessagePackのTimestamp型は、ナノ秒精度の時刻を扱います。マイクロ秒やピコ秒ではなくナノ秒にした理由は、いくつかの近年のプログラミング言語がナノ秒のサポートを追加しているためです。ピコ秒をサポートする言語はほとんど見つかりませんでした。
また、ナノ秒は32ビット以下(30ビット)でちょうど表現できる一方で、マイクロ秒は20ビットでこれは16ビットを超えており、ピコ秒の表現には40ビットも必要になるため、効率の上でもきりが良く有利です。
- Java 6 (Date): ミリ秒
- Java 7 (Instant): ナノ秒
- C# (DateTime): 100ナノ秒
- Rust (std::time::Instant): ナノ秒
- Go (Time): ナノ秒
- Ruby (Time):
ナノ秒任意の有理数。ピコ秒以下も表現可能 - Python (datetime): マイクロ秒
- Elixir (DateTime): マイクロ秒
- C (struct timespec): ナノ秒
- PostgreSQL (timestamptz): マイクロ秒
- MySQL (DATETIME(6)): マイクロ秒
追記:Rubyの精度が間違っていたので修正しました。ピコ秒以下の精度をサポートするシステムもいくつかあるようです:
ちなみに、言語じゃないですが、高精度な時刻を扱える例としては SQLite, EXIF, pax が任意精度 (10進で小数点以下任意長)、DB2 が 1ps, NTPv4 が 2**-64秒単位などといった例があるようです。
— Tanaka Akira (@tanaka_akr) 2017年8月10日
JSONとの互換性
JSONとMessagePackの両方に対応するアプリケーションは、比較的よくあるMessagePackのユースケースの一つです。JSONにはTimestamp型が無いため、MessagePackにおけるTimestamp型をJSONではどう表現するべきでしょうか?
JSONで時刻を表現する方法は標準化されていませんが、Github API、Github GraphQL API、 Facebook Graph APIなどを見ると、ISO-8601形式、つまり YYYY-MM-DD “T” hh:mm:ss “Z” 形式の表示が一般的になりつつあるように見えます。Open API 3.0.0(Swagger)でも、ISO-8601形式と互換性のあるRFC 3339形式を採用しています。
つまり、MessagePackのTimestamp型を使って値をシリアライズするケースで、JSONにも対応したい場合には、YYYY-MM-DD “T” hh:mm:ss “Z” 形式を使用すれば良いでしょう。
バージョニング
MessagePackの仕様にバージョンを付けようと思っています。 Timestamp型が追加される前のバージョンを2.0、追加された後のバージョンを2.1とし、過去のBinary型やExtension型が入る前のバージョンをさかのぼって1.0とする案です。GithubへのPull Requestはこちら:(作業中)
*1:「概念時刻」「絶対時刻」の用語は timestamp with time zone型はタイムゾーン情報を持っていない から取りました
続々・リトライと冪等性のデザインパターン - あらゆる操作を冪等にする方法
いつも心に冪等性。古橋です。
リトライと冪等性のデザインパターンの完結編です。
だいぶ間が空いてしまいましたが! 最後に冪等性を実装する汎用的な実装手法についてまとめていきます。
パターン6:操作ログとリクエストIDでUPDATEを冪等にする
同じIDで識別される値がUPDATEされる場合、つまりmutableである値の管理は、一般に冪等に行うのが難しい。
例えば、ユーザーごとに「最後に購入したアイテム」を更新する操作を考えてみると:
1. ユーザーAが最後に購入したアイテムをアイテム1に変更する(UPDATE)
2. ユーザーAが最後に購入したアイテムをアイテム2に変更する(UPDATE)
この操作に何の対策もなくリトライを実装した場合、後続のUPDATE処理の結果を古い内容で上書きしてしまう可能性がある:
1. ユーザーAが最後に購入したアイテムをアイテム1に変更する(UPDATE)→失敗!
2. ユーザーAが最後に購入したアイテムをアイテム2に変更する(UPDATE)→成功
3. ユーザーAが最後に購入したアイテムをアイテム1に変更する(UPDATE)をリトライ→成功。内容が巻き戻る!
このような処理を冪等にする方法はいくつもあるが、操作ログとリクエストIDを使う手法は非常に汎用性が高い。覚えておけば色々な場面に適用できる。
具体的には、mutable(書き換え可能)な値を扱う代わりに、immutable(不変)なログを扱うことにする:
1. 購買操作ID XXX 08:00=ユーザーAがアイテム1を購入(Create)→失敗!
2. 購買操作ID YYY 10:00=ユーザーAがアイテム2を購入(Create)→成功
3. 購買操作ID XXX 08:00=ユーザーAがアイテム1を購入(Create)をリトライ→成功
値を取り出すときは、操作に付けられた時刻に基づいてログをソートし、最新の物を使えばいい。
操作ログに付けるIDと時刻は、操作自体が行われた時に生成した物を使う必要がある。操作ログを挿入する瞬間の時間を使うと、リトライ時に書き込んだ古い内容が新しい操作だと誤判定されてしまうので要注意。
操作ログを扱う場合、時間が経つにつれてレコード数が増えていき、ストレージ容量を圧迫してくる。このため、古い操作ログを削除したり別ストレージに移す処理を追加する必要が出てくる。しかし、ゴミ掃除が必要になるほど操作ログが溜まるということは、良く使われるサービスを提供しているということなので、最初のうちは実装をサボるのも手かもしれない *1 。
パターン7:最終奥義「トランザクション」
あらゆる操作は冪等であることが望ましい。冪等ならば自動的にリトライできるので信頼性を高めやすいし、リトライしても副作用が無いと分かっていれば障害発生時に対処もしやすい。
しかし冪等性を組み込もうと考えると、どうしてもコードが複雑(難解)になってしまう。
そういう場合にはトランザクションを活用することができる。トランザクションは一連の操作を「すべて成功」(全体を確定する)または「すべて失敗」(全体を巻き戻す)のどちらかになるように保証してくれる。一連の操作の中に一つでもリトライを検出できる操作が入っていれば、簡単に全体の冪等性をできる。
例えば、「アイテムが購入されたら、所定の更新処理を色々と行う」というケースを考えてみる。「所定の更新処理」は複雑で、どうにも冪等な実装が煩雑だとしよう。一方で「アイテムを購入する」の方は、操作にIDを付けて冪等にしたとする。これら全体を単一のトランザクションとして実行することで、全体を冪等にすることができる:
1. アイテム1を購入 操作ID XXX→成功
2. アイテム1の購入に紐付く、所定の更新Aを行う→成功
3. アイテム1の購入に紐付く、所定の更新Bを行う→成功
4. アイテム1の購入に紐付く、所定の更新Cを行う→失敗!
5. すべての処理を完全に巻き戻す
6. アイテム1の購入をリトライ
7. …
これなら所定の更新操作A,B,Cの個々の操作は冪等ではなくても、リトライされるときには何も無かったことにされているか、アイテム1の購入 操作ID XXXが既に完了しているので、全体としては冪等性になる。パターン6の例も、この方法を使えばよりシンプルに冪等にすることができる。
ただし、トランザクションが使えるのは、(現在一般に運用されている技術では)単一のRDBMS上で処理が完結する場合くらいで、外部のREST APIや外部のストレージへの操作を伴う場合は、それら個々の操作を冪等にする必要がある。
XAプロトコルによるTwo-phase commitなど、複数のDBにまたがった操作を単一のトランザクションで実行する方法もあるが、分散トランザクションの技術についてはここでは触れないことにする。
パターン4:操作を細かくして信頼性を高める の冒頭でも触れたように、リトライの粒度を大きくすれば信頼性は落ちるという点には注意が必要。例えば上記のケースでは、「所定の更新操作C」が3%の確率で失敗する場合、「アイテム1の購入」も3%の確率で道連れにされ失敗する。信頼性が要求される操作と失敗しやすい操作が混じっている場合は、同一のトランザクションで実行すると悪影響が大きい。失敗しやすい操作は非同期で実行することで、トランザクションの粒度は小さく保った方がいいだろう。
おわりに
3回に渡る記事(初回・2回目)となりましたが、いかがだったでしょうか。何とか完結させました…元々はTreasure Dataの同僚とリトライに関する議論をするときに、基礎知識として共有する内容を書こうと思ったのがきっかけでしたが、あらゆる場面で分散システムの知識が要求される昨今のプログラミング環境においては、リトライと冪等性は必修科目なのではないかと思われます。
FluentdやEmbulkなどのデータを扱うシステムはリトライを前提にした設計をする必要があり、Digdagもエラーを重複なくリトライすることが重要なシステムなので、大いに役に立っています。Digdagの実装では、実際にほぼすべてのREST APIとDB操作が冪等になっており、エラーが起きても自動でリトライするようになっています。いま手がけているリアルタイムデータ処理システムでも、PlazmaDBの実装で使用しているパターンの多くを再利用しています。
*1:この手抜きは多くの場合に妥当だと思う。ただし消費ストレージ容量をモニタリングする監視やアラートは追加しておいた方がいい。
日本OSS貢献者賞を受賞しました
このたび、第10回 日本OSS貢献者賞 を受賞いたしました。
非同期メッセージングライブラリ「MessagePack」、分散Key-Valueストア「kumofs」、ログコレクタ「Fluentd」、バルクデータローダ「Embulk」、Presto向けゲートウェイサーバ「Prestogres」など、大学生時代から現在に至るまで、多数のOSSプロジェクトを立ち上げ、開発を主導している。2010年度 日本OSS奨励賞を受賞。
推薦していただいた皆様、審査員の皆様、ありがとうございます。もちろん、OSSは1人で作っている物ではありません。かつては名も無いOSSに果敢にも参加していただいた皆様、本当にありがとうございます。
何年も前からコミュニティを支えていただいているMessagePackの開発者の皆様や、Fluentdのコミッタやコントリビュータの皆様、Embulkプラグイン、Fluentdプラグインの開発に携わる皆様、ドキュメントやブログ記事を書いている皆様、OSSを継続できる環境を作っているTreasure Dataの同僚、色々な人々の努力で成り立っています。
いつもいつも、お世話になっております。まだまだ新しいOSSを設計していく所存です。これからもよろしくお願いします!
Embulkでやりたいことリスト(2015年7月版)
バルクロード機能
1つの設定ファイルで複数ジョブを実行する
例えば users.csv と histories.csv の2つのファイルを、それぞれPostgreSQLにある users と histories の2つのテーブル にロードしたいというようなユースケースに対応する機能。
設定ファイルの構文はissueに書いてあるように、default: に書き並べた設定に対して、jobs: に書いた設定をマージしたものを実際の設定ファイルとして実行していく方法で良さそう。しかし、fliters: は配列なので、default: に書かれた filters: に jobs: に書かれた filters: をどうマージするか、あまり良い案がない。常に後ろに追加すれば良いわけでは無いと思うので。
filtersが配列になっているのが良くないので、これを transform: {name: config, name: config, ...} というmapにすれば、うまくマージできる。例えば、
jobs:
accounts:
in:
path_prefix: accounts
parser:
type: csv
columns:
- {name: id, type: long}
- {name: surename, type: string}
- {name: givenname, type: string}
transforms:
remove_my_sensitive_columns:
columns: [id]
out:
table: accounts
payments:
in:
path_prefix: payments.csv
parser:
type: csv
columns:
- {name: id, type: long}
- {name: timestamp, type: timestamp, format: format: '%Y-%m-%d %H:%M:%S.%N'}
out:
table: payments
requests:
in:
path_prefix: requests.csv
parser:
type: csv
columns:
- {name: request_id, type: string}
- {name: account_id, type: long}
- {name: timestamp, type: timestamp, format: format: '%Y-%m-%d %H:%M:%S.%N'}
transforms:
remove_my_sensitive_columns:
columns: [account_id]
out:
table: requests
in:
type: file
transform:
remove_my_sensitive_columns:
type: filter_column
columns: []
out:
type: postgresql
table: ${table_name}
複数のジョブを実行するときに、全部を1つのトランザクションとして扱うか、1つ1つのジョブを別々のトランザクションと考えて逐次実行するかは、決まっていない。全部を1つのトランザクションにする場合、全ジョブが完了するまでcommitできないので、実装は比較的複雑になる。逐次実行する場合は、resume fileのパスをどういうコマンドラインで指定してもらうか、どのタイミングで消すかが良く分かっていない。
エラーレコードの扱いをカスタマイズ可能にする
設定ファイルの構文は、issueに書いてある error: フィールドにoutputプラグインを書く方法で良いと思う。デフォルトでは embulk-output-warning みたいなbuilt-inプラグインが指定されていることにして、警告を出して無視する。カスタマイズ次第で、embulk-output-abort を指定してエラーにさせるとか、embulk-output-file を指定してファイルに保存できるようになる。
どうやって実装するかが悩ましい。とりあえず、embulk-formatter-csv と embulk-parser-csv に実装してみて、良さそうなAPIを考えて、それを全プラグインで使えるようにmix-inかutility classとして切り出す方針が良さそうだと思っている。
JSON型サポート
arrayやmap型などの型付きの複合型を入れるのも良いのだけども、どうせスキーマレスな型は必要になるはずだから、とりあえずJSON型を追加し、arrayやmapなどもそこに突っ込む方針で良いと思う。
プラグインAPIの互換性を壊さずに型を追加できるようにするAPI(Added SwitchPageReader and SwitchPageBuilder utilities. by frsyuki · Pull Request #191 · embulk/embulk · GitHub)も考えたけども、それは要らない気がしている。なぜなら、Javaは静的型付け言語だが処理系は動的で、実行時にメソッドが実装されているかどうかチェックできるから、古いAPIに準拠したプラグインに対する処理をembulk本体側に入れておけば(e.g. メソッドが実装されていなかったらstringに変換してしまう)、後方互換性を維持したままJSON型は追加できる。
json型はPostgreSQLと同様に、arrayやmap以外に文字列などのスカラ型も保存できて良いと思う。fluentdと同様に、内部エンコーディングはmsgpackにすればいい。
BigDecimal型サポート
いるかな?
--no-commit, --no-run オプションの追加
誰かコードを書くんだ…!
プラグインAPI
テストフレームワーク
Help wanted。
全プラグインタイプをRubyで書けるようにする
- Implement JRuby bridge for FileInputPlugin · Issue #21 · embulk/embulk · GitHub
- Implement JRuby bridge for FileOutputPlugin · Issue #22 · embulk/embulk · GitHub
- Implement JRuby bridge for DecoderPlugin · Issue #31 · embulk/embulk · GitHub
- Implement JRuby bridge for EncoderPlugin · Issue #32 · embulk/embulk · GitHub
DecoderとEncoderは、Rubyで書けなくても特に問題ない気がしているけども、FileInputとFileOutputは書けた方が良さそう。
行ベースのパーサプラグインを簡単に書くmixinかユーティリティ
- Add LineParserPlugin base class or LineDecoder bridge for Ruby · Issue #231 · embulk/embulk · GitHub
fluentdで言うところのmixinのような仕組みが、今のところないので、こういう便利系APIをどうやって足したら良いのかの指針がない。まずそこを少し考えた方がいい。
TimestampParser/Formatter APIをstaticに作れるようにする
欲しいプラグイン
Presto filter
filterプラグインは結構書くのが大変で、もっと便利なAPIを追加しないといけない。しかし他方で、大体のユースケースはSQLが書ければ解決できる。
そこで、embulkのfilterプラグインとして、SQLの処理系であるPrestoを使うプラグインがあれば、filterプラグインを書かなくても色々な処理ができるようになる。
具体的な設定ファイルは、例えば:
in:
type: file
...
filters:
- type: presto
query: |-
select ip, address, time + elapsed as end_time from in where address != '127.0.0.1'
out:
type: stdout
のようになる(なって欲しい)。
line-filter decoder
CSVパーサなど、parserプラグインにデータを渡す前に、行を加工したりスキップしたいことが、たまにある。
例えば、行のフォーマットが
2015-06-01 23:15:81 {"col1":"val1","col2":2}
というように日付 + JSONになっている場合に、日付部分を削除してからJSONパーサプラグインに渡したい、というケース。
parserプラグインに渡す前のデータは、decoderプラグインで加工できる。そういう加工をするプラグインを一つ作ればいい。
各種改善
outputプラグインの並列化
タスクの個数(taskCount)はinputプラグインが決めるのだけども、ファイルが1つしか無いケースや、embulk-input-jdbc など並列化に対応していないプラグインを使っていると、outputプラグインの動作までシングルスレッドで動くことになってしまう。
よくあるoutputの処理が遅いケースでは、inputは1スレッドでもoutputをマルチスレッドで動かしたいことが良くある。
実はtaskCountは、executorプラグインのレイヤーで変更することができる。executorプラグインは、inputプラグインから受け取ったデータをoutputプラグインに渡す部分をカスタマイズできるのだけども、そこでデータを複数スレッドに分散させればいい。
LocalExecutorPluginを改造すればできる。少し難しいのは、resumeはタスク単位で行われるので、resumeした結果が冪等になるように、データの分散はinput + 設定ファイルに対して決定性のあるアルゴリズムで行わなければならないところだけ。
統計情報の収集
処理したレコード数、バイト数、CPU使用率、メモリ使用量などの統計情報の収集。
Dropwizardのmetricsを組み込めば良さそう。依存関係も少ないし。
組み込み方に関する具体的な設計は、まだ何も無い。
LineDecoderの最適化
issueに貼ってある参考実装みたいにしたい。
現在のLineDecoderは、厳密にはデータの末端にある1行の扱いがおかしい。
その他
Github issuesに登録してあるissue全部:
Re: 論理削除はなぜ「筋が悪い」か
Kazuhoさんの論理削除はなぜ「筋が悪い」かを読んで。
UPDATEが発生しないテーブルならば、削除フラグを使った実装手法でも現在の状態と更新ログを別々に表現でき、結果として効率と過去の情報を参照できるメリットを簡潔に両立できるのではないか、という話。
大前提として全く同意なのだけども、今あるテーブルにdeleted_atを足すだけで、過去のレコードを復旧可能なようにしたい>< みたいに思っちゃった僕のような人間が実際に取るべき実装手法は何か、あるいは、それを想定して今やっておくべきテーブル設計はどういうものか!?というのが最後の疑問。
まずUPDATEがなければ、immutableなマスタ、更新ログ、「現時点のビュー」の3テーブルは、例えば次のようになる(PostgreSQLの場合):
-- immutableなマスタ。 create table records ( id serial primary key, another_col uuid not null ); -- 更新ログ。deleted_atカラムがある。 create table record_delete_events ( record_id int primary key references (records.id), deleted_at timestamp with time zone not null default now() ); create index delete_events_deleted_at on record_delete_events (deleted_at); -- 現時点のビュー。マスタから更新ログに含まれるidを取り除いたVIEW。 create view live_records as select * from records where id not exists (select * from record_delete_events where record_id = id); -- 削除する操作。更新ログにINSERT INSERT INTO record_delete_events (record_id) values (1);
削除フラグを使った実装手法でも、まったく同じスキーマを定義できる:
-- immutableなマスタ。deleted_atカラムは無視する。 create table records ( id serial primary key, another_col uuid not null, deleted_at timestamp with time zone defualt null ); create index records_deleted_at on records (deleted_at) where deleted_at is not null; -- 更新ログ。マスタからdeleted_atがセットされたレコードを抽出したVIEW。 create view record_delete_events as select id as record_id, deleted_at from records where deleted_at is not null; -- 現時点のビュー。マスタからdeleted_atがセットされていないレコードを抽出したVIEW。 create view live_records as select id, another_col from records where records where deleted_at is null; -- 削除する操作。UPDATEでdeleted_atをセット UPDATE records SET deleted_at = now() WHERE id=1;
上記のクエリは、live_recordsからprimary key以外の条件でSELECTする際に、部分インデックスrecords_deleted_atが必要になるので最適化が効きにくくなる弊害が残るが、これは次の実装手法で解決できるはず:
-- 現時点のビュー。新しいレコードはここに入れる。 create table live_records ( id serial primary key, another_col uuid not null ); -- 更新ログ。削除したレコードはこっちに移す。 create table deleted_records ( record_id id primary key, another_col uuid not null, deleted_at timestamp with time zone not null default now() ); create index records_deleted_at on deleted_records (deleted_at); create view record_delete_events as select record_id, deleted_at from deleted_records; -- immutableなマスタ。liveとdeletedをUNION ALLしたビュー。 create view records as select id, another_col from live_records union all select record_id as id, another_col from deleted_records; -- 削除する操作: WITH deleted ( DELETE FROM live_records WHERE id=1 RETURNING * ) INSERT INTO deleted_records (record_id, another_col) SELECT id, another_col
ただし、PostgreSQLでは、UPDATEの負荷とDELETE+INSERTの負荷があまり変わらないと仮定する。削除する操作が複雑になっているが、これはFUNCTIONを作っておくことで回避できる:
CREATE FUNCTION delete_record (delete_record_id int not null) as $$ WITH deleted ( DELETE FROM live_records WHERE id=delete_record_id RETURNING * ) INSERT INTO deleted_records (record_id, another_col) SELECT id, another_col $$ language sql; select delete_record(1);
VIEWではなくINHERITでも実装できるはず。おそらくこうなる:
-- immutableなマスタ。親テーブルからのSELECTは、子テーブルのレコードを含む create table records ( id serial primary key, another_col uuid not null ); -- 現時点のビュー。子テーブル。 create table live_records ( ) inherits (records); -- 更新ログ。子テーブル。 create table deleted_records ( deleted_at timestamp with time zone not null default now() ) inherits (records); create view record_delete_events as select id as record_id, deleted_at from deleted_records;
ここで疑問は、
- 効率的にSELECTや更新ができるスキーマを作ろうとすると、VIEWやFUNCTIONなど、側に実装するコードが増えてくる。それらのコードは、上記のようにDB側に実装しても良い(するべき)だろうか?それともアプリケーションに実装するべきだろうか?
- WebサービスとかTreasure Dataのようなサービス事業者だと、テーブルを最初に設計するときにあまり時間をかけられないので、後から見直して最適化していくことが多い。テーブルのスキーマは停止時間なしで変更する手法をいくつか思いつくが(PostgreSQLなら)、上記のレコードを削除する操作などはアプリケーションの変更を伴うので難しい(アプリケーションとDBのスキーマをアトミックに変更できない)。
*1:でもPlazmaDBの実装は、ほぼ全部FUNCTIONになっている… Plazma - Treasure Data’s distributed analytical database -
Embulk 0.3 & 0.4 の新機能 - リジュームとJavaプラグイン
つい先日*1、Embulk の新しいメジャーバージョンを2つリリースしました。
これらのバージョンでは、データ転送ミドルウェア勉強会で得られたフィードバックを元に、リジューム機能、Javaプラグイン機能、そして プラグインテンプレートジェネレータ を追加しています。
リジューム機能
大きなデータをロードする場合、大部分のデータのロードには成功するが、一部だけ失敗してしまうことは良くあることです。ネットワーク障害、サーバの過負荷などの他に、エラー処理が不完全であるなど原因は様々考えられますが、そのためだけに全データをすべてロードし直すのは大変な手間です。
そこでEmbulkでは、分割された複数のタスクのうちの一部だけが失敗した場合に、それらのタスクを後からリトライできる仕組みを導入しました。
使い方は、embulk run に --resume--state PATH オプションを指定するだけです:
embulk run config.yml --resume-state resume.yml
もしロードが一部失敗した場合は、指定したファイルに実行状態が保存されます。これをリトライしたい場合は、 まったく同じコマンドを再実行 すればOKです:
embulk run config.yml --resume-state resume.yml
それでも失敗してしまった場合には、また resume.yml ファイルが更新されるので、また同じコマンドを実行すればOKです。
一部ではなくすべてのタスクが失敗してしまった場合には、resume.yml ファイルは作成されません。しかしいずれにしても、まったく同じコマンドでリトライできます。
もしもリトライを諦めて中間データを掃除したい場合は、run の代わりに cleanup を実行してください:
embulk cleanup config.yml --resume-state resume.yml
リジュームの内部実装
例えば3つのタスクのうちの最後のタスクが失敗した場合は、このようなresume.ymlファイルが作成されます:
in_schema: # 入力スキーマ
- {index: 0, name: file, type: string}
- {index: 1, name: hostname, type: string}
- {index: 2, name: col0, type: long}
- {index: 3, name: col1, type: double}
out_schema: # 出力スキーマ
- {index: 0, name: file, type: string}
- {index: 1, name: hostname, type: string}
- {index: 2, name: col0, type: long}
- {index: 3, name: col1, type: double}
in_task: # inputプラグインのtask
files: [file1, file2, file3]
hostname: null
out_task: # outputプラグインのtask
TimeZone: UTC
in_reports: # 成功したinputタスクのcommit reports
- {records: 10} # 成功したタスクのレポート
- {records: 10} # 成功したタスクのレポート
- null # 失敗した分
out_reports: # 成功したoutputタスクのcommit reports
- {} # 成功したタスクのレポート
- {} # 成功したタスクのレポート
- null # 失敗した分
exec_task:
transaction_time: '2015-02-24 20:49:04.729 UTC'
transaction_time_zone: UTC
in_reports と out_reports には、実行したタスクのレポート(CommitReport)が書かれています。ここがnullであるタスクは、前回の実行時に失敗したタスクです。resume時には、これらのタスクのみを再実行します。タスクを再実行して成功すれば、そのnullを実際のレポートに置き換えることができるわけです。
そうして全てのタスクのレポートが揃ったら、それらのレポートを集めてプラグインに返し、トランザクションをコミットさせます。
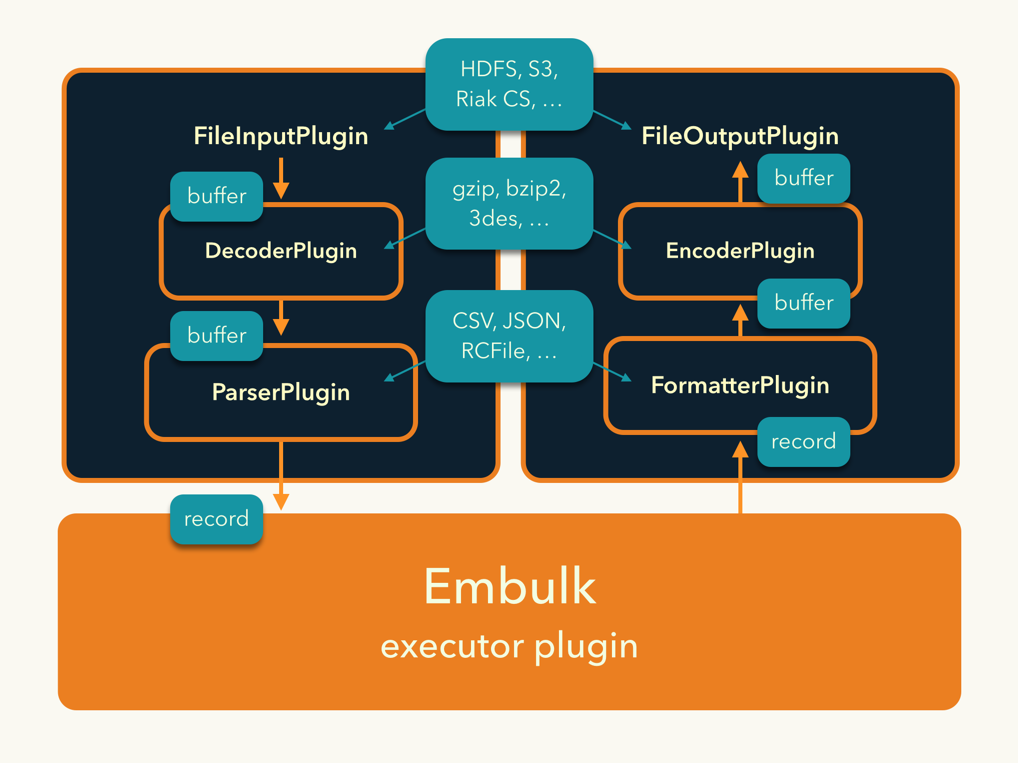
並列バッチデータ転送OSSのEmbulkをソースコードリーディングしてみる(その3:run概要&データソース概要 でも触れられていますが、タスク(TaskSource) や CommitReport などのデータをファイルに保存し、後で復元してやり直したり、ネットワーク越しに転送して分散実行できることが、Embulk の実装上の大きな特徴です。
HadoopのInputSplitやConfiguration、PrestoのHandleなどにも見られるように、タスク・オブジェクトのシリアライズはEmbulkのような並列・分散処理フレームワークにおいて必須の実装課題です。しかしシリアライズコードの実装は煩雑な上にバグると発見しにくく、できるだけ素直に隠蔽するべきです。Embulkでは jackson-databind、Proxy、独特な継承構造によって、それなりにうまく解決していると思います。Embulk が提供する Task インタフェースと @Config を使っている限り、プラグインでは意識する必要が無いようになっています。
Javaプラグイン機能
Embulk 0.3以前はRubyでしかプラグインを書くことができませんでしたが、0.4からJavaでも書けるようになりました。
Embulk のプラグインローダーは、新しいClassLoaderを各プラグインごとに作ります。これが何を意味するかというと、プラグインごとに異なるバージョンのライブラリを同時に使える と言うことです。
例えば、Hadoop 1.x 系の HDFS からデータを読み出す file input plugin を書いたとします。そのデータを Hadoop 2.x 系の HDFS に書き出す file output plugin も書いたとします。これらのプラグインを同時にロードするとどうなるでしょうか? ふつうのJavaアプリケーションでは、依存ライブラリのバージョンが衝突し、おそらくうまく動きません。しかしEmbulkでは、各プラグインごとに別々の実行環境を作るため、異なるバージョンのライブラリを同時に使用することが可能です。
プラグインテンプレートジェネレータ
Embulk には、プラグインの開発を簡単にするために、プラグインのひな形を作成する機能が実装されています。 例えば、Rubyでデータ加工を行うプラグインを書きたいと思ったら、次のように始めることができます:
embulk new ruby-filter myfilter
これによって ./embulk-filter-myfilter ディレクトリが自動的に作成され、ほぼ動く状態のコードも同時に生成されます。 あとは実際に必要なコードを足していくだけで、新しいプラグインを開発できます。
*1:1ヶ月前
並列データ転送ツール『Embulk』リリース!
こんにちは。古橋です。
先日の*1 データ転送ミドルウェア勉強会で、新しいオープンソースツール Embulk をリリースしました。
Embulk は、リアルタイムなログ収集では常識となった fluentd のバッチ版のようなツールで、ファイルやデータベースからデータを吸い出し、別のストレージやデータベースにロードするためのコンパクトなツールです。
fluentd と同様にプラグイン型のアーキテクチャを採用 しているため、RubyやJavaで簡単なコードを書くことで、様々なファイルフォーマットやストレージに対応することができます。一方で fluentd とは異なり、高速性やトランザクション制御、スキーマを使ったデータのバリデーション などにこだわっており、1発実行、あるいは日次や1時間毎に実行するバルク処理に特化しています。
なぜEmbulkを作ったのか?
fluentdをリリースした2011年と比較すると、データ収集を取り巻く問題は飛躍的に改善されました。fluentdにログを流し込んでさえいれば、あとはfluentdの設定次第でどんなストレージやサービスにもログを転送できるようになりました。
つまり、用途もなく“とりあえず” 集め始めたログであっても、それがfluentdに入ってさえいれば、集計やグラフ化、監視とアラート、さらには複雑な 異常値検出 や SQLによるストリーミングデータ処理 など、必要になればすぐに価値ある情報を取り出すことが可能です。カンだけに頼らないデータ活用時代においては、何はなくともまずデータの収集基盤を作ることは、非常に重要なステップです。
しかしその一方で、
- ダウンロードしてきた『CSVファイル』を1回ロードして解析してみたい
- 実は10GBもあるので大変。
- 加えて値の変換にカスタムな処理が必要。
- fluentdを導入したけど大量に残った過去データもロードして解析したい
- 実は数年分のデータが溜まっている。
- 全部バイナリデータで扱いに困っている。
- 日次のバッチ処理の一部にデータの転送処理がある
- 実は誰かが書いたか分からないスクリプトがたまに失敗していて困る。
- リトライするにもオプションが多すぎて良く分からない。
- 異なるストレージにデータを同期したい
- MySQLにあるデータをElasticsearchにバルクロードしたい
- ローカルのOracleにあるデータをSalesforce.comに転送したい
- ローカルのHadoopからTreasure Dataに移行したい
- MongoDBからPostgreSQLに移行したい
など、fluentdでカバーすることが難しい問題も多くあることが分かってきました。
そこで、データ収集にまつわる残りすべての問題を解決することを目指したツールがEmbulkです。
Embulkの特徴
プラグインアーキテクチャ
Embulkの第一の特徴はプラグインアーキテクチャです。入力、出力、フィルタ(データ加工)などのプラグインを書くことで足りない機能を補完し、現場で使えるツールに拡張していくことができます。
それらのプラグインは、オープンソースソフトウェアとして自由にリリースすることができます。Embulkのリリースからわずか3週間しか経っていないにもかかわらず、なんと既に17個ものプラグインがリリースされています。
データ処理には、壊れた値(例外データ)の扱いや、エラー処理やリカバリ、日付フォーマットの変換、NULL値の扱い、リトライ、二重ロードを防ぐ冪等性の制御…などなど、実は難しい処理が数多くあります。これらを頭の中に秘伝のタレとして蓄積するだけでなく、多くの人と共有することで、ノウハウが詰まったスクリプトを継続的にメンテナンスできるようにしたいという願いがあります。
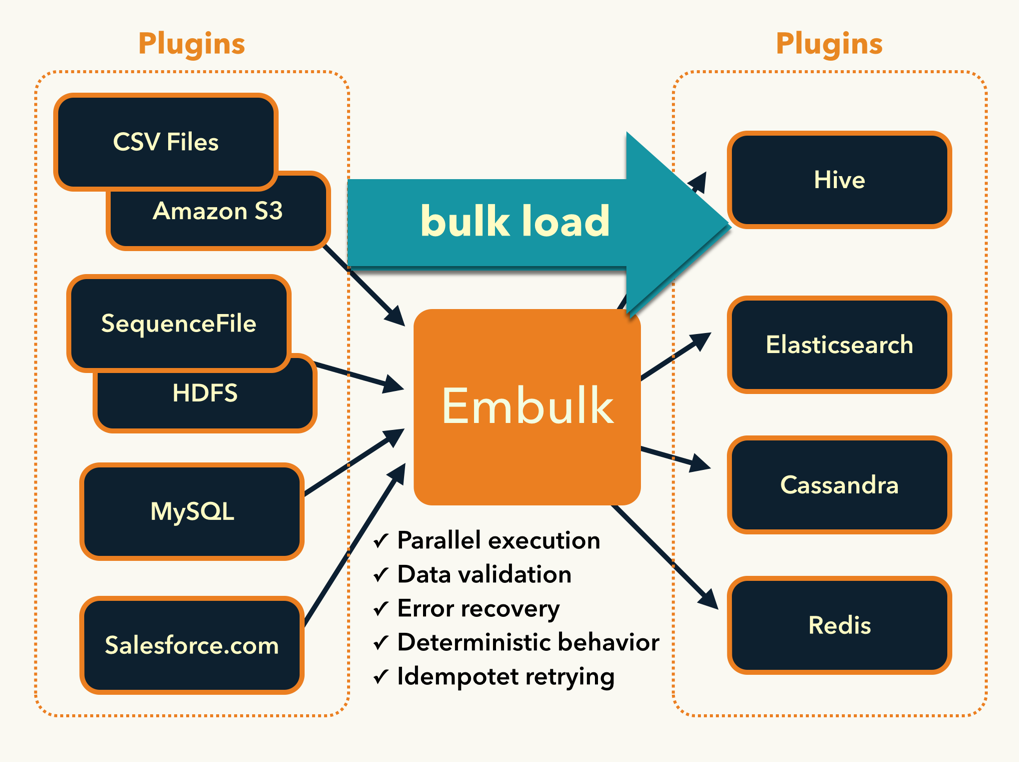
高速な並列・分散処理
Embulkは、1回の処理を複数のタスクに分割し、並列に実行する仕組みを備えています。これらのタスクを実行するExecutorプラグインを追加することで、HadoopやYARN、あるいはSun GridやMPIなどの分散処理環境を使い、大規模データを高速にバルク処理することが可能になります(※なる予定です。未実装。たぶんv0.6くらい)
また、プラグインはRuby(JRuby)で書きますが、Embulkのコア部分はJavaで書かれており、単一スレッドの性能にもこだわっています。もちろん、プラグインまでJavaで書くこともできます(v0.4〜)。特に性能を追求する場合はJavaで書いた方が良いかもしれません。
プラグインはJVMで動く言語なら何でも良いので、ScalaやClojureでも書ける…はず。
guess機構 — 設定ファイルの推測と提案
CSVは、RFCでフォーマットが定義されているにも関わらず、細部が微妙に異なるフォーマットが氾濫していることで悪名高いフォーマットです。これを扱うためにEmbulkのCSVファイルパーサプラグインには、8つもの挙動オプションがあります。挙動オプションの他にも、全カラムの型やカラム名、日付フォーマットの指定などが必要になり、設定項目はどうしても多くなってしまいます。
こういった設定作業を簡単にするために、Embulkには guess という仕組みがあります(v0.1〜。v0.5〜強化予定)。1度少しだけデータを読み込み、自動的に設定ファイルを生成してくれます。このように推測された設定を、必要なら少し手直ししてから使うことで、ゼロから設定を書くよりもずっと素早くデータ処理を始められます。
また、実行フェーズとguessフェーズを分離することによって、一度設定ファイルを固定してしまえば、その後は非決定的な動作がなく、データによらず正しく動き続けるという利点もあります。
どの程度の推測が可能なのかは、実際にEmbulkのQuick Startを試してみてください。
リトライとリジューム
データサイズが大きくなればなるほど、リトライの重要性は増してきます。数百個のタスクがすべて1回で成功するように祈る代わりに、Embulkでは失敗したタスクだけを後からやり直すリジューム機能を備えています(v0.3〜)。
オープンソース
Embulkはオープンソースソフトウェアです。ソースコードはすべてGithubにあります。何か問題が起きたならば、ソースコードを見て対応することができますし、必要なら直して再ビルドすることまでできます*2。
またEmbulkはオープンソースの大原則に従い、複雑な製品で遠大な問題を解決するよりも、シンプルなツールで目の前の問題を解決するツールを目指しています。それ以上のことは他のツールと連携して解決する方向性です。
Embulkプロジェクトへの参加には、色々な方法があります:
- プラグインを書く
- pull-requestを送る
- 他のソフトウェアと連携するツールを書く
- twitterでつぶやく
- ブログを書く
- こんなプラグインを書いた
- こんな環境で使った
- ここが便利そう! ここが足りない!
- 動いた! 動かない!
リリースして3週間しか経っていない、まだまだ若いソフトウェアです。様々な形での参加を待っています!
あわせて読みたい
既にいくつものブログ記事を書いていただいています。ありがとうございます!