並列データ転送ツール『Embulk』リリース!
こんにちは。古橋です。
先日の*1 データ転送ミドルウェア勉強会で、新しいオープンソースツール Embulk をリリースしました。
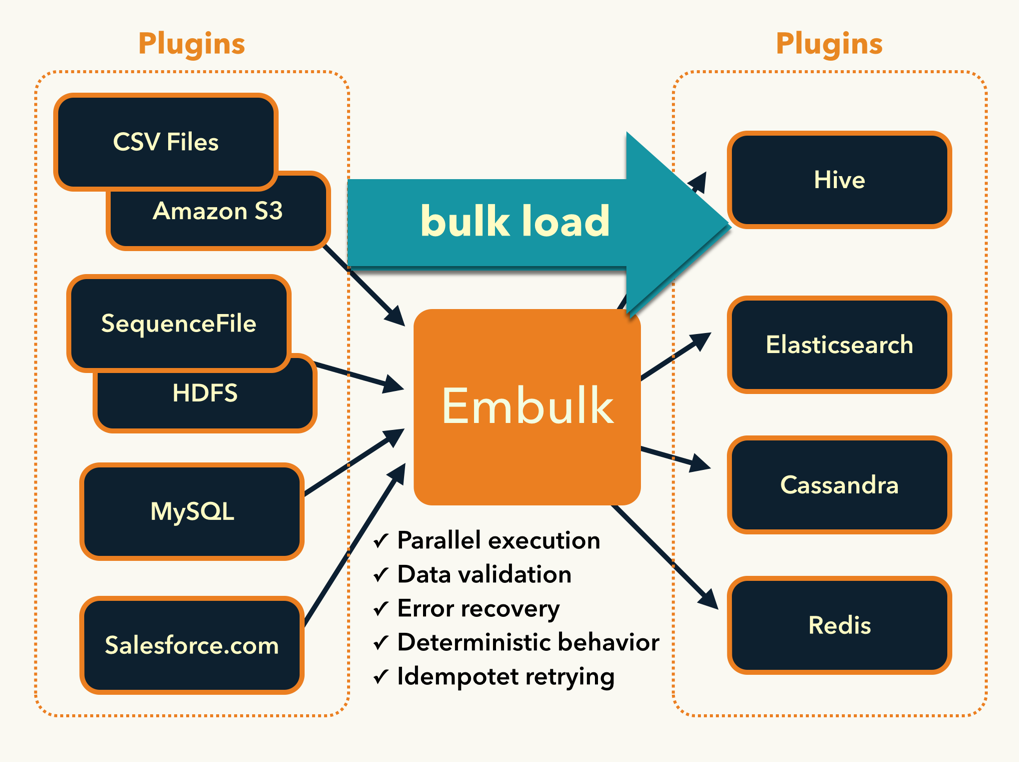
Embulk は、リアルタイムなログ収集では常識となった fluentd のバッチ版のようなツールで、ファイルやデータベースからデータを吸い出し、別のストレージやデータベースにロードするためのコンパクトなツールです。
fluentd と同様にプラグイン型のアーキテクチャを採用 しているため、RubyやJavaで簡単なコードを書くことで、様々なファイルフォーマットやストレージに対応することができます。一方で fluentd とは異なり、高速性やトランザクション制御、スキーマを使ったデータのバリデーション などにこだわっており、1発実行、あるいは日次や1時間毎に実行するバルク処理に特化しています。
なぜEmbulkを作ったのか?
fluentdをリリースした2011年と比較すると、データ収集を取り巻く問題は飛躍的に改善されました。fluentdにログを流し込んでさえいれば、あとはfluentdの設定次第でどんなストレージやサービスにもログを転送できるようになりました。
つまり、用途もなく“とりあえず” 集め始めたログであっても、それがfluentdに入ってさえいれば、集計やグラフ化、監視とアラート、さらには複雑な 異常値検出 や SQLによるストリーミングデータ処理 など、必要になればすぐに価値ある情報を取り出すことが可能です。カンだけに頼らないデータ活用時代においては、何はなくともまずデータの収集基盤を作ることは、非常に重要なステップです。
しかしその一方で、
- ダウンロードしてきた『CSVファイル』を1回ロードして解析してみたい
- 実は10GBもあるので大変。
- 加えて値の変換にカスタムな処理が必要。
- fluentdを導入したけど大量に残った過去データもロードして解析したい
- 実は数年分のデータが溜まっている。
- 全部バイナリデータで扱いに困っている。
- 日次のバッチ処理の一部にデータの転送処理がある
- 実は誰かが書いたか分からないスクリプトがたまに失敗していて困る。
- リトライするにもオプションが多すぎて良く分からない。
- 異なるストレージにデータを同期したい
- MySQLにあるデータをElasticsearchにバルクロードしたい
- ローカルのOracleにあるデータをSalesforce.comに転送したい
- ローカルのHadoopからTreasure Dataに移行したい
- MongoDBからPostgreSQLに移行したい
など、fluentdでカバーすることが難しい問題も多くあることが分かってきました。
そこで、データ収集にまつわる残りすべての問題を解決することを目指したツールがEmbulkです。
Embulkの特徴
プラグインアーキテクチャ
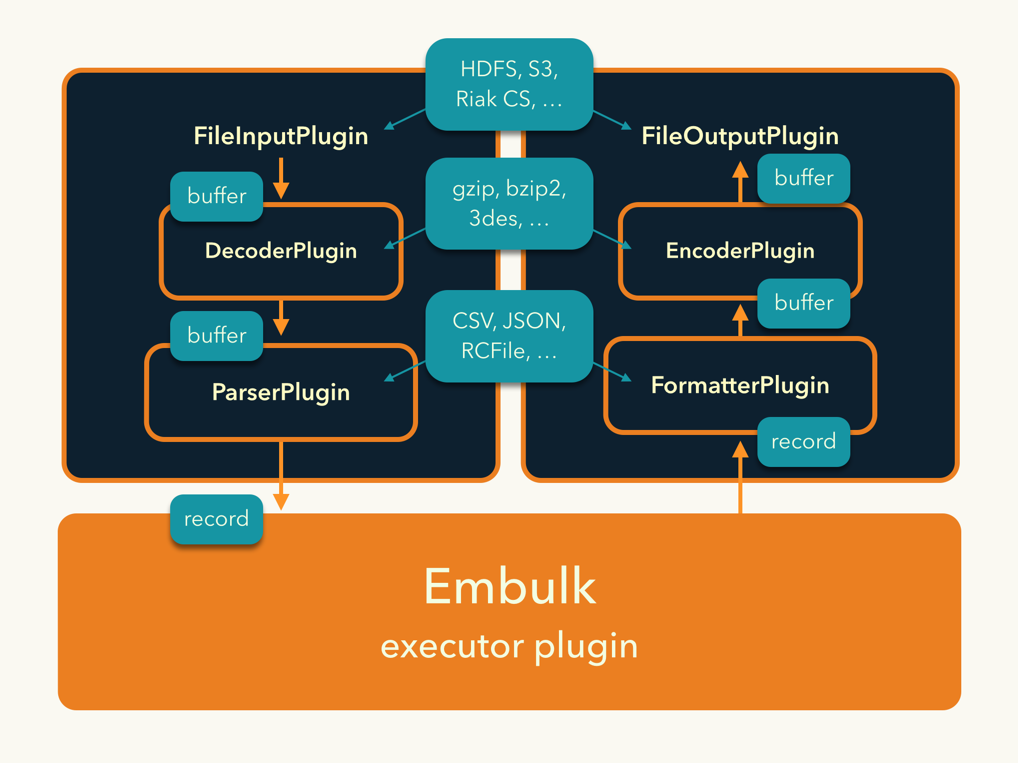
Embulkの第一の特徴はプラグインアーキテクチャです。入力、出力、フィルタ(データ加工)などのプラグインを書くことで足りない機能を補完し、現場で使えるツールに拡張していくことができます。
それらのプラグインは、オープンソースソフトウェアとして自由にリリースすることができます。Embulkのリリースからわずか3週間しか経っていないにもかかわらず、なんと既に17個ものプラグインがリリースされています。
データ処理には、壊れた値(例外データ)の扱いや、エラー処理やリカバリ、日付フォーマットの変換、NULL値の扱い、リトライ、二重ロードを防ぐ冪等性の制御…などなど、実は難しい処理が数多くあります。これらを頭の中に秘伝のタレとして蓄積するだけでなく、多くの人と共有することで、ノウハウが詰まったスクリプトを継続的にメンテナンスできるようにしたいという願いがあります。
高速な並列・分散処理
Embulkは、1回の処理を複数のタスクに分割し、並列に実行する仕組みを備えています。これらのタスクを実行するExecutorプラグインを追加することで、HadoopやYARN、あるいはSun GridやMPIなどの分散処理環境を使い、大規模データを高速にバルク処理することが可能になります(※なる予定です。未実装。たぶんv0.6くらい)
また、プラグインはRuby(JRuby)で書きますが、Embulkのコア部分はJavaで書かれており、単一スレッドの性能にもこだわっています。もちろん、プラグインまでJavaで書くこともできます(v0.4〜)。特に性能を追求する場合はJavaで書いた方が良いかもしれません。
プラグインはJVMで動く言語なら何でも良いので、ScalaやClojureでも書ける…はず。
guess機構 — 設定ファイルの推測と提案
CSVは、RFCでフォーマットが定義されているにも関わらず、細部が微妙に異なるフォーマットが氾濫していることで悪名高いフォーマットです。これを扱うためにEmbulkのCSVファイルパーサプラグインには、8つもの挙動オプションがあります。挙動オプションの他にも、全カラムの型やカラム名、日付フォーマットの指定などが必要になり、設定項目はどうしても多くなってしまいます。
こういった設定作業を簡単にするために、Embulkには guess という仕組みがあります(v0.1〜。v0.5〜強化予定)。1度少しだけデータを読み込み、自動的に設定ファイルを生成してくれます。このように推測された設定を、必要なら少し手直ししてから使うことで、ゼロから設定を書くよりもずっと素早くデータ処理を始められます。
また、実行フェーズとguessフェーズを分離することによって、一度設定ファイルを固定してしまえば、その後は非決定的な動作がなく、データによらず正しく動き続けるという利点もあります。
どの程度の推測が可能なのかは、実際にEmbulkのQuick Startを試してみてください。
リトライとリジューム
データサイズが大きくなればなるほど、リトライの重要性は増してきます。数百個のタスクがすべて1回で成功するように祈る代わりに、Embulkでは失敗したタスクだけを後からやり直すリジューム機能を備えています(v0.3〜)。
オープンソース
Embulkはオープンソースソフトウェアです。ソースコードはすべてGithubにあります。何か問題が起きたならば、ソースコードを見て対応することができますし、必要なら直して再ビルドすることまでできます*2。
またEmbulkはオープンソースの大原則に従い、複雑な製品で遠大な問題を解決するよりも、シンプルなツールで目の前の問題を解決するツールを目指しています。それ以上のことは他のツールと連携して解決する方向性です。
Embulkプロジェクトへの参加には、色々な方法があります:
- プラグインを書く
- pull-requestを送る
- 他のソフトウェアと連携するツールを書く
- twitterでつぶやく
- ブログを書く
- こんなプラグインを書いた
- こんな環境で使った
- ここが便利そう! ここが足りない!
- 動いた! 動かない!
リリースして3週間しか経っていない、まだまだ若いソフトウェアです。様々な形での参加を待っています!
あわせて読みたい
既にいくつものブログ記事を書いていただいています。ありがとうございます!