The Kumofs Project
分散key-valueストア Kumofs のWebサイトをオープンしました!

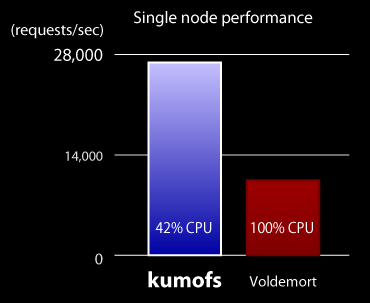
Webサイトには、LinkedIn で開発された分散Key-valueストアである Voldemort との速度比較を掲載しています。
kumofsはVoldemortと比べて、倍以上の読み込み性能を、半分以下のCPU使用率で達成できます。
kumofsは並列イベント駆動I/Oを基盤とした、マルチコアCPUに特化したスケーラブルな実装です。
ノード間の通信には、MessagePack のゼロ・コピー化されたデシリアライザを活用しています。
MessagePackのストリームデシリアライザは(kumo-gatewayのmemcachedプロトコルのパーサも)、ちょっと賢いバッファリング戦略を実装しています。
コマンドを受け取るたびに新しいバッファを確保するのではなく、複数のコマンドで1つのバッファを共有します:
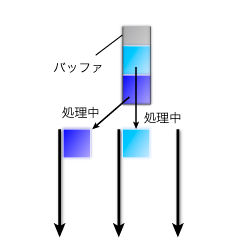
複数のスレッドでバッファを共有すると、その寿命の管理が難しくなりますが、バッファの先頭に参照カウンタ埋め込むことで制御しています。
バッファが足りなくなったときは、バッファが共有されていればmalloc()で新しいバッファを確保し*1、共有されていなければ先頭に巻き戻して再利用します。
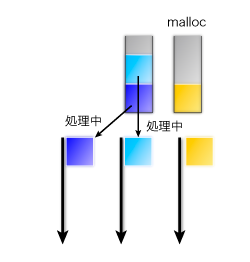
これによってmalloc()を呼び出す回数を大幅に削減できます。特に数バイト程度の細かい通信を頻繁にやりとりするケースでは、1秒間に1万回以上のmalloc()を削減できる計算になります。
kumofsのプロファイルを採ると、malloc()やfree()の呼び出しにかかるコストは無視できないほど高い事が分かります。malloc()の呼び出し回数を減らすことで性能を向上させることができ、仮想メモリの使用量を削減できる効果も得られます。
kumo-gatewayとkumo-serverの間では、毎回コネクションを張り直さずに常に接続を維持しているため、この最適化はより効果的に働きます。
このバッファの実装はmpioライブラリにも含まれています。
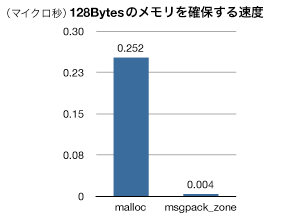
さらにC++版MessagePackには、zoneというメモリの管理を効率的に行う機構が含まれています。
簡単に言えばシングルスレッド専用のメモリプールなのですが、malloc()と比べて圧倒的に高速にメモリを確保することができます:
kumofsでは、新しいメッセージを受け付けるとzoneを作成し、あるスレッドがそのメッセージを処理している限りは、そのzoneから優先的にメモリを確保していきます。
非同期処理のメモリ管理にもzoneを使っています*2。
と、このあたりでCPUの利用効率に差が出てくるのだろうと思われます。
…影ながら大きな理由は、Voldemort は Java で実装されている一方、kumofs は C++ で実装している点だと思いますが^^;