イベントログ収集ツール fluent リリース!
こんにちは。Treasure Data の古橋です^^;
先日の Treasure Data, Inc. 壮行会 で、イベントログ収集ツール fluent をリリースしました!
fluent は syslogd のようなツールで、イベントログの転送や集約をするためのコンパクトなツールです。
ただ syslogd とは異なり、ログメッセージに テキストではなく JSON オブジェクト を使います。また プラグインアーキテクチャ を採用しており、ログの入力元や出力先を簡単に追加できます。
Twitterでも話題沸騰中です:イベントログ収集ツール #fluent 周りの最近の話題
背景
「ログの解析」は、Webサービスの品質向上のために非常に重要です。Apacheのアクセスログだけに限らず、アプリケーションからユーザの性別や年齢などの詳しい情報を集めることで、価値ある情報を数多く抽出することができます。
しかし、これらの イベントログをどうやって集めるか? という問題があります。ログを吐き出すアプリケーションは、複数のサーバに分散しています。それらのログを1箇所に集約してくる必要があります(とはいえ SPOF になってしまうのはイヤですね)
あるいは Amazon S3 や HDFS に書き出したくなります。その他にも Cassandra や MongoDB などに書き出したいケースもあります。ファイルに書き出すなら日付ごとにファイルを分けて欲しいし、当然圧縮もして欲しい。できればプラグインで拡張できると非常に嬉しいところです。
fluent は、これらの問題をシンプルに解決するイベントログ収集ツールです。
イベントログの転送とHA構成
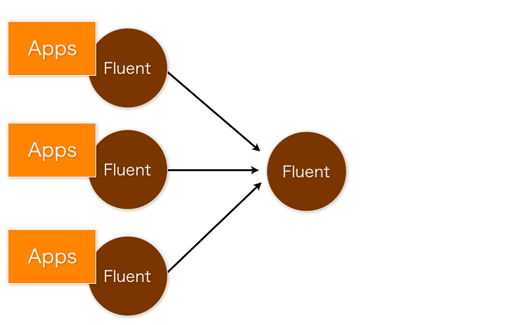
fluent を使うと、↓このようにイベントログを転送したり、ルーティングすることができます。

転送先のサーバがダウンしていたら、バックアップサーバに切り替える機能もあります:
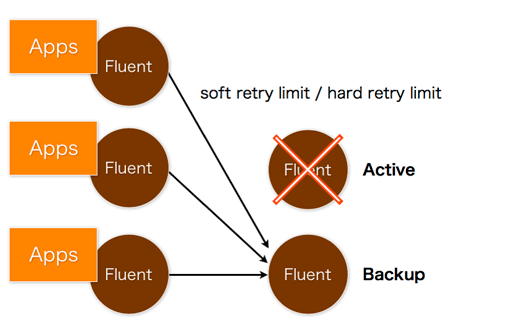
ちなみにラウンドロビンで負荷分散することもできます。これらの機能はすべてプラグインで拡張することができます:Fluent plugins
アーキテクチャ
fluent は全面的にプラグインアーキテクチャを採用しています。コア部分は小さいプログラムで、その他はすべてプラグインで成り立っています。

プラグインには次の3種類があります:
- Input plugin
- アプリケーションや他のサーバからログの受け取ったり、様々なデータソースから定期的にログを取り寄せてきます。
- Buffer plugin
- ログをバッファリングし、スループットを向上させたり、信頼性を向上させる役割を担います。
- Output plugin
- ログをストレージに書き出したり、他のサーバに転送したりします。
Input plugin や Output plugin は、Rubyを使って簡単に書くことができます:Writing plugins
また、RubyGemsでプラグインを配布・インストールすることができます。↓このコマンドで、現在リリースされているプラグインの一覧を見られます:
$ gem search -rd fluent-plugin
まだリリースから数日しか経っていませんが、実は既に MongoDB プラグインや S3 プラグインが公開されています^^; 非常に簡単に書けるようになっているので、バシバシと拡張してみて下さい。
fluent のリポジトリは github にあります:http://github.com/fluent
構造化ロガー
多くのアプリケーションでは、人間が読むことを前提としたテキスト形式のログを書き出していることが多いと思いますが、今後はプログラムで処理しやすくするために、構造化されたログに移行していく必要があるでしょう。
テキスト形式のログをパースして構造化する*1という方法もまだまだ必要そうですが、アプリケーションが直接構造化されたログを書き出す方がずっとシンプルです。
そこで、各種のプログラミング言語向けに、構造化されたログを書き出せるライブラリが欲しくなります。標準的なテキスト形式のロガーを拡張する方法や、別に作って両方使う方法など、色々な実装手段がありそうです(腕の見せ所ですね)
というわけで、Ruby で fluent 向けの構造化ロガーを実装しました。fluent 向けと言っても、設定次第でファイルやsyslogに書き出すこともできます。
fluent/fluent-logger-ruby - GitHub
MessagePack-Hadoop Integration (HBase勉強会)
Hbase勉強会(第二回)で発表したスライドを公開しました:
MessagePack+Hadoop (HBase-study 2011-06-16 Japan) - Scribd

MessagePackとHadoopを連携させるプロジェクトは、github の msgpack/msgpack-hadoop で進行中です。
HBase や Hive で、非構造化データを効率よく扱えるようにすることを目指しています。データはとりあえず突っ込んで、スキーマやクレンジングは後で考えたい(変更したい) というニーズにピッタリ合うハズです。
ログ収集ツールFluentも、オープンソースで公開するべく現在準備中です。
Fluent は、Facebook が開発したログ収集ツールである Scribe と似たツールです。Scribe がメッセージの表現として文字列しか使用できないのに対し、Fluent は JSON で表現可能なあらゆるオブジェクトを扱える点が大きく異なります(もちろん、内部では高速な MessagePack を使用しています)。
ログ収集ツールというよりは、汎用的なイベント収集ツールと言った方が良いのかもしれません。
プラグイン機構も異なります。Scribe はプラグインでデータの書き出し先を追加することができますが、Fluent ではデータの入り口も自由に追加することができます(Scribe では Thrift しか使えない上に、Thriftのインストールが面倒なのが難点で…)。
乞うご期待^^;
MessagePack IDL 仕様案
先日のMessagePackハッカソンで議論した、MessagePack IDL の仕様についてまとめます。
実際のユースケースを元に、大規模な分散アプリケーションまでカバーできる実践的な仕様を目指しました。
基本的な文法
IDLは、大きく分けて 型の定義 と サービスの定義 に分かれます。
型の定義では、RPCでやりとりしたりログに保存したりするメッセージの構造を定義します。この構造の定義から、各言語のクラス定義や、シリアライズ・デシリアライズを行うコードを生成したりするのが、IDL処理系の役割の一つです。
サービスの定義では、RPCのインタフェースを定義します。この定義からクライアントやサーバのコードを生成します。
コメント
# これはコメント // これもコメント /* これもコメント /* ネストしても */ 良いではないか */
型の定義
message
メッセージ型は↓このように定義します:
# 組み込み型 message BasicTypeExample { # <id>: <type> <name> 1: byte f1 2: short f2 3: int f3 4: long f4 5: ubyte f5 6: ushort f6 7: uint f7 8: ulong f8 9: float f9 10: double f10 11: bool f11 12: raw f12 13: string f13 } # 総称型 message ContainerTypeExample { 1: list<string> f1 2: map<string,string> f2 3: map<string, list<string,string>> f3 # 総称型はネスト可能 } # optionalとrequired message OptionalExample { 1: string f1 # required non-nullable # デフォルトはrequired 2: required string f2 # required non-nullable 3: optional string f3 # optional non-nullable } # ? を付けるとnullableになる message NullableExample { 1: string? f1 # required nullable # デフォルトはrequired 2: required string? f2 # required nullable 3: optional string? f3 # optional nullable }
exception
exceptionは例外を定義します。messageとほぼ同じですが、生成されるコードが変わってきます:
exception NotFound {
1: string message
} # この例外の文字列表現は "NotFound"
# 継承ができる
exception KeyNotFound < NotFound {
# 基底クラスの最大のID(この場合は1: string message)以下のIDは使えない
2: raw key
} # この例外の文字列表現は "NotFound.KeyNotFound"
拡張仕様
採用されるかもしれないけど、とりあえず最初の実装では見送る仕様です。
デフォルト値
messageのフィールドや関数の引数にデフォルト値を設定できると便利です。
パーサの実装は難しくないのですが、右辺値と左辺値の型があっているかどうか検査する実装が大変そうな気がします(そうでもないかも)。コンテナ型にデフォルト値を設定できるようにすると、mapやlistのリテラルが存在しない言語でコード生成が大変になります。
実装する場合でも、コンテナ型のデフォルト値は設定できないようにする案が有力です。
message DefaultValueExample {
1: optional ulong flag = 1 # デフォルト値の指定
2: optional raw? value # nullableなフィールドのデフォルト値はnull
3: optional string message # nullableでないフィールドのデフォルト値は0,空文字列,falseなど
}
typedef
型に別名を付ける構文です。typedefはIDL処理系の中で完結し、実際のコードの中には現れないという案と、現れた方がいいという案があります(Javaではどうすれば良いのでしょう…)
typedef ulong NodeId typedef map<string,string> PropertyMap
typespec
言語やアプリケーションごとに型をカスタマイズする構文です。
よく使う型には便利なメソッドが実装されているクラスを使いたいし、クラスを詰め直す処理も書きたくない場合など、欲しくなる機能です。
typespec cpp PropertyMap std::tr1::unordered_map<std::string,std::string> # typedefに対するtypespec typespec MyApp1 DefaultValueExample.value myapp::Value # フィールドのtypespec typespec MyApp2 DefaultValueExample myqpp::MyClass # 型に対するtypespec
サービスの定義
RPCインタフェースは service で定義し、複数のserviceをまとめて application を宣言します。
service間では名前空間が分かれており、serviceが異なれば同名の関数を宣言できます。
serviceは複数のバージョンを宣言することができ、互換性を保ったまま新しいバージョンを追加ができます:
service StorageService:0 { # <name>:<version>
raw? get(1: raw key)
void add(1: raw key, 2: raw value) throws DiskFullError
ulong getDiskFreeSize()
}
service StorageService:1 {
# 前のバージョンのメソッド一覧も全部書く
raw? get(1: raw key)
void add(1: raw key, 2: raw value)
# 無くなったメソッドは書かない
# 追加したメソッドも普通に書く
map<raw,raw>? getAttributes(1: raw key)
void setAttributes(1: raw key, 2: map<raw,raw> attrs) throws DiskFullError
}
service StatusService:0 {
ulong getDiskFreeSize()
}
application MyApp {
# <service>:<version> <scope> default?
StorageService:1 storage default
StatusService:0 status
}
サーバ側のコード生成
新しいバージョンの関数は、デフォルトでは古いバージョンの関数を呼んで欲しいが、古いバージョンと挙動が異なることもあります。
オブジェクト指向言語ではなかなか実現が難しそうですが、関数を関数オブジェクトとして扱えばスマートに解決できそうです:
// serviceは、関数の一覧をメンバ変数としてコード生成 class StorageService_0 { Function<raw? (raw)> get Function<void (raw, raw)> add Function<ulong ()> getDiskFreeSize } class StorageService_1 { Function<raw? (raw)> get Function<void (raw, raw)> add Function<map<raw,raw>? (raw)> getAttributes Function<void (raw, map<raw,raw>)> setAttributes } class StatusService_0 { Function<ulong ()> getDiskFreeSize } // applicationは、シングルトンのインスタンス object MyApp { // 宣言されたserviceを、過去のバージョンを含めて保持 StorageService_0 storage_0; StorageService_1 storage_1; StatusService status_0; // serviceの関数には初期値が設定されている: // 古いバージョンの関数が存在すれば、古いバージョンの関数を呼び出す関数 storage_1.get = (raw key) => storage_0.get(key) storage_1.add = (raw key, raw value) => storage_0.add(key, value) // そうでなければ、例外を投げる関数 storage_0.get = (raw key) => throw new org.msgpack.rpc.NotImpelmentedError storage_0.add = (raw key, raw value) => throw new org.msgpack.rpc.NotImpelmentedError storage_0.getDiskFreeSize = () => throw new org.msgpack.rpc.NotImpelmentedError storage_1.getAttributes = (raw key) => throw new org.msgpack.rpc.NotImpelmentedError storage_1.setAttributes = (raw key, map<raw,raw>) => throw new org.msgpack.rpc.NotImpelmentedError status_0.getDiskFreeSize = (raw key, raw value) => throw new org.msgpack.rpc.NotImpelmentedError }
関数を実装する場合は、このように関数オブジェクトを代入します:
// 関数を代入して処理を実装 MyApp.storage_0.get = (raw key) => { return ... } // 新しいバージョンで挙動が変わった場合でも対応可能 MyApp.storage_1.get = (raw key) => { return ... } // 互換性を維持するためには、古い関数も実装しておく(実装を残しておく) MyApp.storage_0.getDiskFreeSize = () => { return ... } MyApp.status_0.getDiskFreeSize = MyApp.storage_0.getDiskFreeSize
クライアント側のコード生成
クライアント側では、バージョンの選択に加えて、どの名前空間(scope)の関数を呼ぶか? という点が問題になってきます。
まず、アプリケーションではこのように使います:
// アプリケーションからはこのように使う: MyApp remote = new MyApp(host, port) StorageService_1 storage = remote.storage().version1() storage.add("key", "value") // add:storage:1 を呼ぶ storage.get("key") // get:storage:1 を呼ぶ StatusService_0 stat = remote.status().version0() stat.getDiskFreeSize() // getDiskFreeSize:stat:0 を呼ぶ
これは↓このようなコードを生成すると実現できます:
// serviceは、RPCを行う関数を実装したクラス(直接インスタンス化はできない) abstract class StorageService_0 { raw? get(raw key) void add(raw key, raw value) throws DiskFullError ulong getDiskFreeSize() } abstract class StorageService_1 { raw? get(raw key) void add(raw key, raw value) map<raw,raw> getAttributes(raw key) void setAttributes(raw key, map<raw,raw> attrs) throws DiskFullError } interface StorageService { StorageService_0 version0() // バージョン0のRPCインタフェースを返す StorageService_1 version1() // バージョン1のRPCインタフェースを返す } abstract class StatusService_0 { ulong getDiskFreeSize() } interface StatusService { StatusService_0 version0() // バージョン0のRPCインタフェースを返す } // applicationはファクトリークラス class MyApp { MyApp(host, port); StorageService storage() StatusService status() }
拡張仕様
採用されるかもしれないけど、とりあえず最初の実装では見送る仕様です。
メタサービス
サービスの情報を取得するサービスがあると非常に便利です。例えば、サーバ側のバージョンを取得して処理を分岐したりできます。
applicationには暗黙的に組み込みのメタサービスが存在することにすると、きれいにまとまりそうです:
# メタ関数を提供する組み込みのサービスが定義されていることにする service BuiltInService:0 { # 指定されたscopeの最新バージョンを返す int getVersion(1: string scope) } # applicationの定義では... application MyApp { StorageService:1 storage default StatusService:0 status BuiltInService:0 _ # このscopeが暗黙的に存在することにする }
サーバ側では、BuiltInServiceの実装はコード生成器が自動的に生成します。
クライアント側では、このような関数を提供します:
MyApp remote = new MyApp(host, port) int v = remote.storage().getVersion() // メタ関数の呼び出し // この呼び出しと同じ: int v = remote._().version0().getVersion("storage") // 接続先のバージョンによって処理を分岐するクライアントを書ける switch(v) { case 0: return remote.storage().version0() defaut: /* 将来もversion 1がサポートされ続けることを期待 */ return remote.storage().version1() }
同様にして、serviceに定義されている関数の一覧を取得する機能も実現できそうです。Rubyで使いたくなりそうですね。
interface
RPCのクライアント側で、ある特定の関数群だけを使うメソッドを書くことは良くあります。
すべての関数を1つのserviceに記述していると、serviceはバージョンアップ時にクラス名が変わってしまうため、そのserviceを使っているすべてのコードを書き換える必要があります(静的型付け言語の場合)。
interfaceを導入すると、この問題を回避できます:
typedef map<raw,raw> Row
interface TableInterface:0 {
void insert(1: Row row)
Row? selectMatch(1: raw column, 2: raw data)
Row? selectPrefixMatch(1: raw column, 2: raw prefix)
}
interface KeyValueInterface:1 {
void set(1: raw key, 2: raw value)
raw? get(1: raw key)
}
service StorageService:2 {
implements TableInterface:0
implements KeyValueInterface:1
uint getNumEntries()
}
application MyApp {
StorageService storage default
}
interfaceにもバージョン番号を付けられますが、実際にこのバージョン番号がネットワーク上を流れることはありません。コード生成されるクラス名だけに使われます。
サーバ側のコード生成は、単にserviceの中にinterfaceの関数群を取り込んだものを生成します。
# この定義と同じコードを生成:
service StorageService:2 {
void insert(1: Row row)
Row? selectMatch(1: raw column, 2: raw data)
Row? selectPrefixMatch(1: raw column, 2: raw prefix)
void set(1: raw key, 2: raw value)
raw? get(1: raw key)
uint getNumEntries()
}
クライアント側では、serviceをinterfaceにアップキャストして利用できるようにコード生成します。
interface TableInterface_0 { void insert(Row row) Row? selectMatch(raw column, raw data) Row? selectPrefixMatch(raw column, raw prefix) } interface KeyValueInterface_1 { void set(raw key, raw value) raw? get(raw key) } abstract class StorageService_2 implements TableInterface_0, KeyValueInterface_1 { void insert(Row row) Row? selectMatch(raw column, raw data) Row? selectPrefixMatch(raw column, raw prefix) void set(raw key, raw value) raw? get(raw key) uint getNumEntries() }
scopeなしで使う
1つのapplicationを複数のserviceに分割して定義する機能は、複数のモジュールで構成される大規模なプログラムには必要になりますが、ちょっとしたプログラムを書きたいときには不便です。
scopeなしでも使えると、カジュアルなユースケースにも対応できそうです。
サーバ側では、serviceを定義と共に暗黙的に同名のapplicationが定義されると考えれば、シンプルに対応できそうです。
object StorageService { StorageService_0 _0 // scopeが無名 StorageService_1 _1 // scopeが無名 BuiltInService __0 // メタ関数サービス _1.get = (raw key) => _0.get(key) _1.add = (raw key, raw value) => _0.add(key, value) _0.get = (raw key) => throw new org.msgpack.rpc.NotImpelmentedError _0.add = (raw key, raw value) => throw new org.msgpack.rpc.NotImpelmentedError _0.getDiskFreeSize = () => throw new org.msgpack.rpc.NotImpelmentedError _1.getAttributes = (raw key) => throw new org.msgpack.rpc.NotImpelmentedError _1.setAttributes = (raw key, map<raw,raw>) => throw new org.msgpack.rpc.NotImpelmentedError } StorageService._0.get = (raw key) => { return ... } StorageService._1.get = (raw key) => { return ... } StorageService._0.getDiskFreeSize = () => { return ... }
クライアント側では、serviceごとに生成するクラスにクラスメソッドを追加するだけで良さそうです。
abstract class StorageService_0 { static StorageService_0 open(host, port, scope="") } abstract class StorageService_1 { static StorageService_1 open(host, port, scope="") }
第3回MessagePackハッカソン開催報告
4月3日、MessagePackハッカソン第3回を開催しました。
14人のユーザーと開発者が集まり、実際のユースケースを元にしながら多くの問題が解決(への方針が決定)しました。

RPCのバージョニングサポート
背景

ソフトウェアはバージョンアップを繰り返すものですが、分散型のアプリケーションでは、単一のシステムの中で新旧のバージョンが混在して運用されることがあります。昨今のスケーラブルな分散システムでは、システム全体を停止せずに部分的にプログラムをバージョンアップさせていく ローリングアップデート と呼ばれる手法が利用されており、このようなケースでも 新旧のバージョンが互換性を保ったまま相互に通信可能である必要があります。
Thrift では、関数の引数やstructのメンバに optional という修飾子を付けることで、互換性を保ったまま引数やメンバの追加ができるようになっています。
しかし実際には、引数やメンバの追加だけではなく、もっと大きな変更を加えたいケースが多くあります。例えば、バージョン1で A という関数があったが、バージョン2で B と C の2つの関数に分離され、A はまだ呼び出せるが、未来のバージョンで削除される予定なので呼び出すべきではない、というケースがあります。他にも、引数や返り値の型を変更したい場合には、Thriftの方法では対処できません。
- 異なるバージョンで同名の関数を呼び分けたい
- ある機能を実現する一連の関数群があるとき、機能の単位でバージョンを管理したい
- 古いバージョンが呼び出されたときは、警告を表示するようにしたい
プロトコル
MessagePack-RPCのリクエストメッセージは、[REQUEST, msgid, method, args] という4要素の配列です。methodは文字列で、関数名を表しています。
このmethodを、
例: "get:0", "get:1"
互換性の維持のために(また使い勝手のために)、versionは省略可能とします。サーバはversionが省略されていたら、同名の関数の中で最新のバージョンを呼び出すことにします。
IDL
他の要求は IDL で解決します。これは後述します。
RPCの名前空間サポート
背景

1つのサーバプログラムが複数のモジュールから構成されていることは良くあります。それぞれのモジュールを別々の人が設計・実装していることも多いでしょう。それらのモジュールで関数名が重複しないようにするのは、大変な作業です。
RPCの関数名に名前空間を導入することで、このような複雑なアプリケーションをシンプルに実装することができます。
プロトコル
前述のバージョンと同様に、methodを次のように拡張します:
互換性の維持のために、scopeは省略可能とします。サーバはscopeが省略されていたら、デフォルトの名前空間を使うことにします。;
scopeとversionは、どちらも省略可能です。片方だけが省略されていた場合は、次のルールで識別します:
scopeの命名規則:/[a-zA-Z][a-zA-Z_]*/(先頭に数字は使えない)
versionの命名規則:/[0-9]+/(先頭は数字)
RPCのエラー処理
背景
マトモなアプリケーションでは、マトモなエラー処理は必須ですね。返り値でエラーを返すのは、実装もデバッグも大変です。
現在のプロトコルでエラーを返すには、[RESPONSE, msgid, error, result] というメッセージを返します。error と result は任意のオブジェクトです。
このプロトコルでエラーの種類や詳細を返すには、アプリケーション側で対処が必要です。この方法を標準化することで、相互互換性を高めることができます。
考慮すべきことは、エラーの種類はプログラムのバージョンアップ時に変化する可能性があるという点です。
例えば、エラーを細分化(特化)させたいケースがあります。例えば、NotFound というエラーを次のバージョンで KeyNotFound extends NotFound と BucketNotFound extends NotFound に細分化するようなケースです。
プロトコル
エラーを返すプロトコルを [RESPONSE, msgid, error_type, error_object] と拡張します(これもプロトコルの拡張というよりは、既存のプロトコル仕様の上位に新たな標準を加えている)
error_type はエラーの種類を表し、エラーの種類のグループ関係をドットで区切った文字列です。例:"NotFound.KeyNotFound"。
error_object はエラーの詳細を表し、通常は配列です。例:["key not found", "key1"]
クライアントは未知のエラーを受け取ったとき、より親のグループで処理することが可能です。例えば KeyNotFound を知らない古いクライアントが、新しいサーバから "NotFound.KeyNotFound" を受け取った場合でも、NotFound として扱うことができます。
組み込みのエラー
アプリケーション定義のエラーとは別に、MessagePack-RPCのライブラリ側で扱う組み込みのエラーが必要になります。
次のような区分が提案されています:
RPCError
|
+-- TimeoutError
|
+-- ClientError
| |
| +-- TransportError
| | |
| | +-- NetworkUnreachableError
| | |
| | +-- ConnectionRefusedError
| | |
| | +-- ConnectionTimeoutError
| |
| +-- MessageRefusedError
| | |
| | +-- MessageTooLargeError
| |
| +-- CallError
| |
| +-- NoMethodError
| |
| +-- ArgumentError
|
+-- ServerError
| |
| +-- ServerBusyError
|
+-- RemoteError
|
+-- RemoteRuntimeError
|
+-- (user-defined errors)
アプリケーションに近い型の扱い
Javaで、Dateクラスを扱いたいという提案がありました。
今後も様々な型を扱えるようにしたいという要求がどんどん出てくることが予想されます。アプリケーション層に近い型は、その要求の詳細は今後変化していくでしょう。
しかし、下層(MessagePackの型)に新たな型を追加すると、多言語対応が難しくなる、仕様が複雑になる、JSONと相互変換できなくなるなどの問題が発生します。具体的に言えば、BSONようになってしまうという意味です。"Function" や "MD5" という型がプリミティブとして定義されています。Min key という謎の型*1もあります。SHA1は? 多言語対応はできるのでしょうか?
しかし、"対応している言語で" 合意された標準的な方法があれば、相互互換性が高まることは確かです。
そこで、アプリケーションの型をMessagePackの型と対応付けるガイドラインを用意していくことで対応します。
実装としては、MessagePackの型に新たな型を追加する代わりに、MessagePackの型と言語の型を変換するところに新しいコードを追加します。

日付型
7つの案が出ました:
- 基本:epocからの経過時刻を保存する。タイムゾーンはUTCに固定する
- 案1:経過秒を整数で保存
- 案2:経過ミリ秒を整数で保存
- 案3:経過マイクロ秒を整数で保存
- 案4:経過を浮動小数点数で保存(精度は秒またはミリ秒またはマイクロ秒)
- 案5:(経過秒, マイクロ秒)を2要素の配列で保存
- 案6:(整数, 精度)を2要素の配列で保存
- 案7:実装しない(アプリケーションごとに対応する)
ユースケースとしては、「人間」が入力した時刻を記録するにはミリ秒程度の精度があれば十分だが、プログラムが扱うタイムスタンプにはマイクロ秒以上の精度が欲しくなります。
決定的な案が出なかったので、とりあえずJava版では案2の「ミリ秒を整数で保存する」方法でDateクラスのシリアライズを実装してみることになりました。
decimal型
Java版で、BigDecimalクラスを扱いたいという提案がありました。ユースケースとしては、お金の計算に使います。
- 案1:文字列で保存
- 案2:Binary Coded Decimal (BCD) で保存する
- 案3:Densely Packed Decimal (DPD) で保存する(DPDはIEEE 754-2008で標準化されている)
- 案4:実装しない(アプリケーションごとに対応する)
とりあえずJava版で案1と案2(余裕があれば案3?)を実装してみることになりました。
難しいですねぇ…。
Java版:Templateプリコンパイラ
Java版では、ユーザー定義クラスのシリアライズ/デシリアライズを行う Template を、実行時にコード生成してコンパイル・ロードする機能が実装されています。
しかし、Android(DalvikVM)ではクラスを動的にロードできないため、動かない(リフレクションベースの遅い実装にフォールバックする)という問題がありました。また、初回利用時に少し時間がかかるというデメリットもあります。
現在実装中です。
圧縮
長いテキストを扱う全文検索エンジンや、インターネット越しにメッセージのやりとりを行いたいシステムでは、データを圧縮することで性能を向上させることができます。
- 案1:MessagePackの仕様で対応
- 例:0x04 0x00 DEFLATE_STREAM ...
- メリット:アプリケーションは少ない変更で圧縮の効果を得られる
- デメリット:オブジェクトごとの圧縮になるので、圧縮率が低くなる
- デメリット:圧縮アルゴリズムを追加するたびに互換性は失われ、他の言語への移植が難しくなる
- 案2:RPCのプロトコルで対応
- 案3:RPCのトランスポート層にプラグインする
- 例:圧縮TCPトランスポート
- メリット:ストリーム全体で圧縮するので、圧縮率が高くなる
- メリット:トランスポート層のプラグイン機構を使えるため、既存のライブラリは変更せずに済む
- デメリット:サーバとクライアントで同じ圧縮アルゴリズムを使うように、人間が設定する必要がある
- ただしエラーの表示は可能(TransportError)
- 案4:実装しない(アプリケーションごとに対応する)
案3の方針が有力ですが、トランスポート層の仕様までは決まらず、現状ではプラグインの機構に従ってアプリケーションで対応しつつ、良い実装が現れれば標準仕様に取り込むことになりそうです。
プロジェクト
JIRA(チケット管理)とConfluence(WIki)を導入しました。
JIRAはチケットのネストができます。日付型が欲しい→Java版で日付型を実装 というように、言語をまたいだ共通の提案→各言語の実装 という要求にぴったり合います。
それぞれ以下のURLにあります:
IDL
大いに議論が盛り上がりました。次のエントリで詳しくまとめます。
*1:MongoDBで使うようです
Webサイトをgithubで管理してpush時に自動的に同期する方法
Webサーバに Subversion のサーバを立てておき、HTML や CSS を commit することでWebサイトを更新する方法は、良く知られているテクニック、らしいですね*1。更新の履歴を残すことができるし、ましてチマチマとFTPやsftpでアップロードするよりずっと簡単です。
しかし SVN の代わりに git を使おうとすると、pushしてもリポートリポジトリではファイルを更新してくれません。
また、リポジトリはWebサーバ上に作るよりも、便利な管理インタフェースがある github(や噂のgitosis)に置いておきたいところです。
そこで、github の Post-Receive Hook を使うと、リポジトリに変更を push すると同時に、Webサーバにも同期させることができます*2。
Webサーバに同期する前に、Sphinxでドキュメントを整形したり、SassをCSSに変換したり、あるいはJavaのソースからJavaDocを生成したりと、色々な前処理を走らせることもできます。
流れは下図のようになります。Post-Recieve Hook を設定しておくと、リポジトリに変更が push されたときに指定しておいたURLに POST リクエストを送信してくれます。この POST リクエストを受け取ったタイミングで github から変更を pull し、色々な前処理を実行した後に、Webサーバにアップロードすれば完了です。
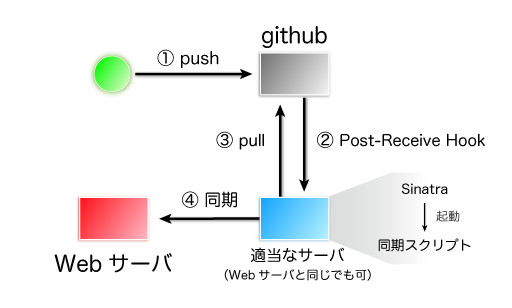
実際に、msgpack.org ではこの方法を使ってWebサイトを管理しています。
サーバスクリプト
まず、github から Post-Recive Hookを受け取って、同期スクリプトを起動する簡単なWebサーバを用意します。
POSTされるデータには、payload というパラメータ名でJSON形式のデータが含まれています。
Ruby の Sinatra を使って書くと↓こうなります。
#!/usr/bin/env ruby require 'sinatra' require 'json' here = File.dirname(__FILE__) SYNC_SCRIPT = "#{here}/update-website.sh" post '/' do begin push = JSON.parse(params[:payload]) system(SYNC_SCRIPT) "ok." rescue "error." end end
同期スクリプト
次に、githubから変更をpullしてWebサーバに同期するスクリプトを用意します。
同期する方法は、同期先のWebサーバで使える方法を選択してください。ここでは ssh + rsync を使ってみます:
- update-website.sh
#!/bin/sh tmpdir=/home/viver/gitsync/work/msgpack-website repo=git://github.com/msgpack/website.git rsyncto=viver@example.com:htdocs/ rsync='rsync -e "ssh -i ~/.ssh/id_rsa_nopass" -vrtl --delete' if [ -d "$tmpdir" ];then cd "$tmpdir" if git pull; then $rsync ./ "$rsyncto" exit 0 fi fi dirname=`dirname "$tmpdir"` basename=`basename "$tmpdir"` mkdir -p "$dirname" cd "$dirname" rm -rf "$basename" if git clone "$repo" "$basename"; then cd "$basename" $rsync ./ "$rsyncto" fi
githubの設定
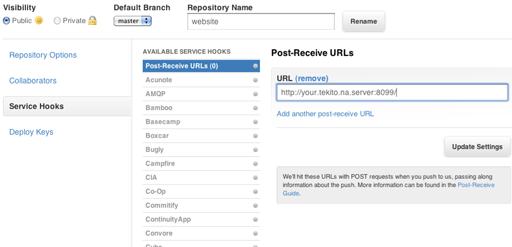
最後に、githubで Post-Receive Hook を発行するURLを設定します。
リポジトリのトップページで [スパナアイコン] Admin ボタンをクリックし、サイドバーから Service Hook を選んで、Post-Receive URLs にサーバスクリプトへのURLを入力してください。
Service Hookの用途
Webサイトにコンテンツを同期する代わりに、push時にテストケースを走らせたり、新しいtagが作成されたタイミングでリリースビルドを作成するなど、発想次第で色々なことができそうです。
面倒な作業はどんどん自動化してみてください^^;
Amazon EC2 で手元のホストとファイルを共有する
Amazon EC2 はVMを好きなタイミングで好きなだけ使うことができるので、複数のサーバを使う分散システムの検証環境として非常に使いやすい*1。費用を計算してみても、自宅でクラスタを動かすことを考えれば、十分安く上がりそうである。
しかし、VMを起動するたびに環境を設定したり、新しいテストを実行するたびにファイルを配ったりするのは面倒なので、ファイルを共有したくなる。
通信の遅延がかなり大きいので、EC2上でssh越しにファイルを編集するのも少々つらい。
そこで、手元のホストとホームディレクトリを共有する。さらに、一度転送したデータはキャッシュさせる。
共有ホームディレクトリ環境の管理方法と組み合わせれば、便利に使えるに違いない。
戦略
ファイル共有には NFSv4 over ssh を使う。NFSv4はポート番号を1つしか使わない(portmapperも要らない)ので、ssh越しで使いやすい。
これに FS-Cache を組み合わせて、データをキャッシュさせる。FS-Cache は Linux 2.6.30 から組み込まれている機能で、メモリだけでなくローカルディスクも使ってデータをキャッシュできるようにする。
NFSv4の設定
手元のホストでは、NFSv4サーバをセットアップしておく*2。 /etc/exportsでは127.0.0.1からのmountを許可しておく。
次にEC2でVMを立ち上る。ディスクイメージには "instance-store" 版のAmazon Linuxを使う。"ebs" 版ではキャッシュデータを置くローカルストレージが使えない*3。
VMが立ち上がったら、sshでログインする。このときに、以下のように2049番ポートを remote port forwarding しておく:
ssh -R2049:127.0.0.1:2049 ec2-user@ec2-host.compute-1.amazonaws.com
ログインしたら、nfs-utilsをインストールする。また、後述するcachefilesdをコンパイルするために、gccもインストールしておく:
yum install nfs-utils gcc
NFSv4サーバとuidを合わせたユーザーを作っておくと、ユーザ管理が簡単になるので便利だろう。
# uidはサーバ側に合わせる useradd -m -u 502 -d /home/viver viver
併せてidmapdの設定が必要になるかもしれない。/etc/idmapd.conf で、"Domain" をサーバの idmapd.conf と同じにしておく:
[General] # The following should be set to the local NFSv4 domain name # The default is the host's DNS domain name. #Domain = local.domain.edu Domain = localdomain
rpc_pipefsをmountし、idmapdを起動する。
mount -t rpc_pipefs rpc_pipefs /var/lib/nfs/rpc_pipefs service rpcidmapd restart
ここで試しにmountしてみる。mountできなければ、何かが間違っている。NFSv4サーバ/クライアント双方のdmesgを見るなどして修正する。
mount -t nfs4 127.0.0.1:/ /mnt umount /mnt
キャッシュの設定
次にFS-Cacheの設定をする。
FS-Cacheを有効にするには、cachefilesdというパッケージをインストールする必要がある。現時点ではyumにバイナリパッケージが用意されていないので、Webサイトからダウンロードして自前でコンパイルする。実は./configureさえ無いので、軽くソースを眺める必要があるかもしれない。
wget http://people.redhat.com/~dhowells/fscache/cachefilesd-0.10.tar.bz2 tar jxvf cachefilesd-0.10.tar.bz2 cd cachefilesd-0.10 make sudo cp cachefilesd /usr/sbin/ sudo cp cachefilesd.conf /etc/
/etc/cachefilesd.conf を編集する。最低限、キャッシュを保存するディレクトリと、SELinuxの設定を書き換える。
キャッシュの保存先はローカルディスク(/media/ephemeral0)とする。SELinuxの設定はコメントアウトする。
#dir /var/fscache dir /media/ephemeral0/fscache tag mycache brun 10% bcull 7% bstop 3% frun 10% fcull 7% fstop 3% # Assuming you're using SELinux with the default security policy included in # this package #secctx system_u:system_r:cachefiles_kernel_t:s0
キャッシュを保存するファイルシステムはuser_xattrが有効になっている必要があるらしいので、remountして有効にしておく。
mount -o remount,user_xattr /media/ephemeral0 mkdir /media/ephemeral0/fscache /usr/sbin/cachefilesd
最後に、キャッシュを有効にしてNFSv4をmountする。キャッシュを有効にするには -o fsc オプションを付ける:
mount -t nfs4 -o fsc 127.0.0.1:/ /mnt mount --bind /mnt/home/viver /home/viver
いくつかファイルを読み込み、キャッシュの保存先ディレクトリを見てみると、サイズが膨らんでいた。きっとキャッシュが効いているのだろう。
$ du -sh /media/ephemeral0/fscache 261M /media/ephemeral0/fscache/
共有ホームディレクトリ環境の管理方法
MacPorts や apt などのパッケージ管理システムでインストールできないアプリケーションやライブラリ、自分で書いたツールなどを、ホームディレクトリにインストールしたいことは良くある。
ホームディレクトリならroot権限が要らないし、rootを持っている場合でも思わぬ操作ミスや設定ミスのリスクを抑えられる利点がある。アンインストールもしやすい。gem や easy_install などのスクリプト言語の管理システムが、OS全体のパッケージ管理システムと競合してしまう問題も回避できる。
このようにホームディレクトリにアプリケーションをインストールするときに、複数のバージョンを同時にインストールしたいことがある。また、異種のOSやCPUアーキテクチャのマシンでホームディレクトリを共有したかったりする*1 *2。
以上のような要求があるときに、ホームディレクトリ環境をどうのように構築し、PATH や LD_LIBRARY_PATH などの環境変数をどのように設定すれば良いか? ./configureするときに、いちいち -I や -L を指定するのも面倒くさい。
なかなか一筋縄では解決しない問題だが、ここでは私の管理方法を紹介する。
ホームディレクトリの構造
ホームディレクトリに ~/arch というディレクトリを作り、この中に 各アーキテクチャ固有のディレクトリ と 特定のホスト固有のディレクトリ を作る*3:
~/arch/ ~/arch/linux-x86_64/ # アーキテクチャ固有ディレクトリ ~/arch/freebsd-i386/ # アーキテクチャ固有ディレクトリ ~/arch/fcore/ # ホスト固有ディレクトリ ~/arch/ucore/ # ホスト固有ディレクトリ ~/arch/net/ # 全ホスト共有ディレクトリ(スクリプトなどを置く)
アーキテクチャ固有ディレクトリやホスト固有ディレクトリの構造は共通で、以下のようになっている:
~/arch/linux-x86_64/ ~/arch/linux-x86_64/app/ ~/arch/linux-x86_64/app/bin/ # ここに PATH を通す ~/arch/linux-x86_64/app/lib/ # ここに LD_LIBRARY_PATH を通す ~/arch/linux-x86_64/app/relink # bin/ や lib/ にシンボリックリンクを作成するツール ~/arch/linux-x86_64/path.conf # path.conf。設定ファイル ~/arch/linux-x86_64/ruby-1.8 # アプリケーションなど。ディレクトリの命名規則は: ~/arch/linux-x86_64/ruby-1.9 # <パッケージ名>-<メジャーバージョン>.<マイナーバージョン> ~/arch/linux-x86_64/msgpack-0.5 # マイナーバージョンが変わったら上書きせずに別のディレクトリに分ける ~/arch/linux-x86_64/msgpack-dev # 自分で開発中のライブラリは -dev にしておくなど ~/arch/linux-x86_64/.bashrc # 固有bashrc
アプリケーションをインストールしたら、app/bin や app/lib にシンボリックリンクを張る。この作業は relink スクリプト(後述)で自動化する。
path.conf ファイルは relinkスクリプトの設定ファイルである。
使い分け
基本的にはアーキテクチャ固有ディレクトリにインストールしていく。
ディストリビューション固有の機能を使っていたり、特定の職場やノートPCなどの環境だけで使うツールは、ホスト固有ディレクトリに置く。
私の場合は、例えば Wi-Fiの設定ツールや、colorgcc などをホスト固有ディレクトリにインストールしている。サーバ用マシンには、システム運用のために開発用とは別バージョンの ruby をインストールしてあったりする。
特定のアーキテクチャやホストに依存しないスクリプトやドキュメントは、全ホスト共通ディレクトリに置く。例えば pdumpfs や mplex、kansit などは全ホスト共通ディレクトリに置いている。
その他に、コマンドプロンプト($PS1)はホスト固有の .bashrc で設定している。
path.conf
path.conf は、.bashrc と relink スクリプトの2つから読み込まれる設定ファイルである。インストールしたアプリケーションのディレクトリ名を書いていく。
内容は↓このようになる:*4
#!/usr/bin/env bash # path_bin はコマンド用 path_bin ruby-1.8 path_bin ruby-1.9 19 path_bin gtest-1.5 # path_lib はライブラリやヘッダ用 path_lib libev-3.9 path_lib luxio-0.2 path_lib gtest-1.5 #path_lib mpio-0.3 #path_lib msgpack-0.5 # 自分で開発している場合はバージョンを -dev にしてみた path_bin kumofs-dev path_bin msgpack-idl-dev path_lib mpio-dev path_lib msgpack-dev path_lib msgpack-rpc-dev
このファイルは、.bashrc と relink スクリプトのどちらから読み込まれたかによって挙動が異なる:
- .bashrcから読み込まれた場合
- $C_INCLUDE_PATH や $LIBRARY_PATH を設定する
- relinkスクリプトから読み込まれた場合
- app/bin/ や app/lib/ にシンボリックリンクを作成する
このように挙動を変える仕組みは、.bashrc と relink スクリプトで function bin_path や function lib_path の定義を変えることで実現している。
C_INCLUDE_PATH や LIBRARY_PATH は gcc で使われる環境変数で、これを設定しておくと毎回インクルードパス(-I)やライブラリパス(-L)を指定しなくて済む。
path_bin には、第二引数に suffix を指定することができる。例えば path_bin ruby-1.9 19 と書くと、ruby-1.9/bin/* 以下のコマンドに 19 という接尾辞が付く。
具体的には、例えば rails とコマンドを叩いたときは ruby-1.8/bin/rails が実行され、rails19 と叩いたときは ruby-1.9/bin/rails が実行されるようになる。
~/.bashrcの実装
~/.bashrc の主な仕事は、アーキテクチャやホスト名を判別することと、関数や変数を定義すること、そしてアーキテクチャやホスト固有の .bashrc を読み込むことである。
アーキテクチャの判別
アーキテクチャやホスト名を判別して、$archdir や $hostdir 変数を定義する。
具体的には、$archdir は ~/arch/darwin-i386 や ~/arch/linux-x86_64 あるいは ~/arch/sunos-i86pc のようになる。
いろいろな方法を試したが、次の定義がポータブルで良さそうである:
kernel=$(uname -s | tr "[A-Z]" "[a-z]") if [ $(uname -p | wc -c) -le $(uname -m | wc -c) ]; then processor=$(uname -p) else processor=$(uname -m) fi export arch=$kernel-$processor export host=$(hostname -s) export archdir="$HOME/arch/$arch" export hostdir="$HOME/arch/$host" export netdir="$HOME/arch/net"
関数や変数の定義
アーキテクチャを定義したら、それにあわせて各種変数や path.conf 用の関数を定義する:
function dev_path() { C_INCLUDE_PATH="$1/include:$C_INCLUDE_PATH" CPLUS_INCLUDE_PATH="$1/include:$CPLUS_INCLUDE_PATH" #OBJC_INCLUDE_PATH="$1/include:$OBJC_INCLUDE_PATH" LIBRARY_PATH="$1/lib:$LIBRARY_PATH" } function net_bin_path() { PATH="$netdir/$1/bin:$PATH"; } function net_sbin_path() { PATH="$netdir/$1/sbin:$PATH"; } function net_dev_path() { dev_path "$netdir/$1"; } function arch_bin_path() { PATH="$archdir/$1/bin:$PATH"; } function arch_sbin_path() { PATH="$archdir/$1/sbin:$PATH"; } function arch_dev_path() { dev_path "$archdir/$1"; } function host_bin_path() { PATH="$hostdir/$1/bin:$PATH"; } function host_sbin_path() { PATH="$hostdir/$1/sbin:$PATH"; } function host_dev_path() { dev_path "$hostdir/$1"; } # path.conf用関数 function path_bin() { echo -n "" # 何もしない } function path_lib() { arch_dev_path "$1" } # PATH と LD_LIBRARY_PATH export PATH="$netdir/app/bin:$archdir/app/bin:$hostdir/app/bin:$PATH" export LD_LIBRARY_PATH="$netdir/app/lib:$archdir/app/lib:$hostdir/app/lib"
path.confと固有bashrcの読み込み
最後に path.conf とアーキテクチャやホスト固有の .bashrc を読み込む:
if [ -f $netdir/path.conf ];then source $netdir/path.conf fi if [ -f $netdir/.bashrc ];then source $netdir/.bashrc fi if [ -f $archdir/path.conf ];then source $archdir/path.conf fi if [ -f $archdir/.bashrc ];then source $archdir/.bashrc fi if [ -f $hostdir/path.conf ];then source $hostdir/path.conf fi if [ -f $hostdir/.bashrc ];then source $hostdir/.bashrc fi export PATH export C_INCLUDE_PATH export CPLUS_INCLUDE_PATH export LIBRARY_PATH
relinkスクリプトの実装
#!/usr/bin/env bash function r { echo "$@" "$@" } function path_bin() { if [ -z "$1" ]; then echo "usage: path_bin() <app> [suffix]" exit 1 fi name="$1" suffix="$2" for f in "$archdir/$name/bin/"*; do if [ ! -f "$f" ]; then continue fi ln="$archdir/app/bin/`basename $f`$suffix" to="../../$name/bin/`basename $f`" rm -f $ln r ln -s "$to" "$ln" done for f in $archdir/$name/sbin/*; do if [ ! -f "$f" ]; then continue fi ln="$archdir/app/bin/`basename $f`$suffix" to="../../$name/sbin/`basename $f`" rm -f $ln r ln -s "$to" "$ln" done } function path_lib() { if [ -z "$1" ]; then echo "usage: path_lib() <app>" exit 1 fi name="$1" for f in $archdir/$name/lib/*; do if [ ! -f "$f" ]; then continue fi ln="$archdir/app/lib/`basename $f`$suffix" to="../../$name/lib/`basename $f`" rm -f $ln r ln -s "$to" "$ln" done } source "$archdir/path.conf"
ホスト固有のrelinkは、$archdir を $hostdir に変える。
新しいアプリケーションをインストールする具体的な手順
何かアプリケーションをインストールするときは、./configure --prefix= でインストール先のディレクトリを指定する:
# 同じアーキテクチャのホストで共有したい場合 $ ./configure --prefix=$archdir/msgpack-0.5 $ make -j4 install # # このホストだけにインストールしたい場合 $ ./configure --prefix=$hostdir/msgpack-0.5 $ make -j4 install
その後で path.conf を書き換え、relink スクリプトを実行する:
# path.conf を書き換える $ echo "path_lib msgpack-0.5" >> $archdir/path.conf # ライブラリの場合 $ echo "path_bin msgpack-0.5" >> $archdir/path.conf # コマンドの場合 # シンボリックを張る $ $archdir/app/relink # ライブラリをインストールした場合は、シェルを再起動する($C_INCLUDE_PATH や $LIBRARY_PATH を設定し直すため)
異なるバージョンをインストールする具体的な手順
基本的には新しいアプリケーションをインストールする場合と同じだが、path.conf の設定方法が異なる。
コマンドの場合は複数のバージョンを共存させることができる。この場合は、path_bin の第2引数に suffix を指定する:
path_bin ruby-1.8 path_bin ruby-1.9 19
共存させる必要が無い場合は、旧バージョンをコメントアウトしておけば良い:
#path_bin ruby-1.8 path_bin ruby-1.9
ライブラリの場合は、新バージョンが後ろに来るように書く。
path_lib msgpack-0.4 path_lib msgpack-0.5
参考文献
- ソースから自前ビルドしたソフトウエアの効率的な管理方法 - (ひ)メモ
- bashrc/vimrc再び。 - ここにタイトルを入力|
まとめ
ホームディレクトリにアプリケーションやライブラリをインストールする際の環境構築方法について紹介した。アーキテクチャやカーネルが異なるホストでホームディレクトリを共有したり、root権限を行使せずにアプリケーションをインストールできるようにするために役立つ。
基本はアーキテクチャやバージョンごとにインストールディレクトリを分け、シンボリックリンクと環境変数で選択するというシンプルな構造だが、その管理タスクを path.conf で自動化している点がミソである。
大学の計算機環境が Mac/Linux/Windows の混成で、友人の間でノウハウを共有しながら管理方法を模索していったところ、このような方法に落ち着いた。今回 カーネル/VM Advent Calendar というイベントがあったので、ちょぃとまとめてみた(長いけど)。
実は問題点は色々ある。読者の皆様のノウハウも共有していただけると幸いである。
Future work
MANPATH も何とかしたい。
path_lib と path_bin を書き分けるのは面倒なので、自動判別して欲しい。
ホームディレクトリにインストールしたサーバアプリケーションも自動起動/自動再起動したいときがある。upstartを使えばできそうだが、D-Busの設定が必要になるかもしれない。
github にあげて欲しい。
Enjoy hacking!!
*1:特に様々なCPUアーキテクチャのマシンを所有している読者の皆様においては、身近な問題だと思われる!
*2:最近は仮想マシンに各種OSを簡単にインストールできるし、i386とx86_64のライブラリはリンクできなかったりするので、マシンが1台しかなくても出番は多い。
*3:昔は「グループ固有ディレクトリ」もあり、任意のグループごとに便利スクリプトや各種設定ファイルを共有できるようにしていた。しかし自宅ネットワーク内にいくつもクラスタがあったりするわけではないので、今ではアーキテクチャ固有ディレクトリを使うことにした。一般に、数が増えると管理が大変になる。
*4:path.conf の先頭には #! を書いているが、直接実行することはなく、他のファイルから source で読み込んで使う。エディタで開いたときに確実にシンタックスハイライトされるので付けているだけ。